操统实验日志 第二章 万丈高楼平地起
关于本章
本章的序将会首先介绍操作系统是如何运行起来的,并在此基础上介绍实现一个完备的操作系统实验需要实现哪些方面,以及这些部分的先后顺序和依赖关系
由于这份文档我并不打算作为一份完备的教程文档来编写,因此语言方面的介绍会相对简略或是跳过,对应的详细介绍可以参考学校的同步教程
在本章的后半部分,将会介绍MBR和中断的相关知识,记录如何编写MBR、测试使用BIOS启动MBR引导程序并通过中断输出字符串进行测试
在下一章节,将会介绍如何从MBR中加载Bootloader并进行更复杂的启动准备操作
序
计算机是如何启动的
这里介绍的启动方式是x86架构下的BIOS启动过程,UEFI启动或是在arm架构下启动则是另一种启动方式
由于本实验使用的是BIOS启动,因此不对UEFI启动和arm架构相关内容进行介绍,有兴趣可以使用搜索引擎进行了解
经典的BIOS启动过程分为了如下五个步骤:
-
加电开机:
按下电源开关以后,电源就会开始向主板和其他设备供电,由于电压还不稳定,主板上的控制芯片组会向CPU发出并保持一个reset信号,初始化CPU。当芯片组检测到电源已经稳定供电则会撤去reset信号,之后CPU立马开始从0xFFFF0处执行指令。需要注意的是,这些指令并不需要我们来编写,它们位于系统的BIOS地址范围内。在0xFFFF0处实际存放的是一个跳转指令,它指向BIOS真正的启动代码的位置,CPU执行该指令后便进入下一步 BIOS启动 过程 -
BIOS启动:
在这一步中,BIOS会进行自检,也称为POST (Power-On-Self-Test),检查系统的关键设备比如内存、显卡等是否正常工作。如果检测到这些关键设备存在致命问题,则会通过蜂鸣音来报告错误,蜂鸣音的长短即次数对应错误类型。在完成自检之后,BIOS就会进入下一步加载MBR并启动 -
加载MBR:
MBR,全称为主引导记录 (Master-Boot-Record) ,它存储在存储设备的首扇区512字节。MBR包含了如下的三个部分:- 启动相关的代码:
在MBR的前446字节中存储了启动引导程序,由于这部分空间太小,没有办法完成很复杂的启动操作,所以计算机会将主要的启动准备操作都放在下一步的bootloader中进行,而这部分引导程序的主要作用就是从磁盘中加载bootloader到内存然后跳转到bootloader的地址上运行 - 磁盘分区记录:
MBR的447~510这64个字节中存储的是分区表信息,每个分区需要16字节,包括了分区的引导标志、起始磁道、起始扇区、起始柱面等信息。这部分分区表最多能够存储四个分区的信息 - 结束标记:
MBR的最后两个字节是一个魔数 (Magic number),通过0xAA55标记这个设备是可以启动的,也就是这512个字节的MBR是有效的
因此在BIOS启动之后,它便会根据设置好的引导顺序,按排位顺序检查引导序列中对应地存储设备是否可以启动 (也就是检查MBR的最后两个字节是否是
0x55AA),如果满足要求,则复制这512字节到内存中的0x7C00地址处,然后跳转到该地址开始执行MBR中启动相关的代码关于为什么MBR是被加载到
0x7C00,而不是加载到0x0000,可以参考Why BIOS loads MBR into 0x7C00 in x86 ?这篇文章 - 启动相关的代码:
-
加载bootloader:
在CPU跳转到0x7C00处之后,就会开始执行MBR中的代码,这部分代码将会由我们编写。在这部分代码中,MBR会从磁盘加载bootloader的代码进入内存,进入保护模式,然后跳转到bootloader处执行 -
加载kernel:
进入bootloader以后,操作系统会进行相当多准备操作,例如加载文件系统、开启分页机制等,在完成这些工作之后,bootloader会从文件系统中装载系统内核进入内存,然后跳转到内核执行当进入内核以后,操作系统就基本完成了启动的过程,内核会完成后续操作系统的初始化操作,这些将留到编写内核的时候再详述
启动过程不是绝对的,从MBR之后的启动方式可以按照自己的设计进行
例如,在MBR中可以加载类似grub的代码,在第一阶段加载文件系统,然后从系统路径里加载第二阶段的代码,并且在第二阶段中实现多系统引导,加载对应系统的kernel文件然后跳转运行
前序知识
在这一章节中将会介绍在后续实验中将会大量使用的基础知识,包括了nasm的语法以及常用概念的解释等
这些内容大部分在用到的时候也会在文章中再次出现
所以如果想要尽快开始实验,不妨跳过这个章节,继续后面的内容
nasm语法
IA-32 处理器
IA-32处理器是指从Intel 80386开始到32位的奔腾4处理器,是最为经典的处理器架构
其有三种基本操作模式:保护模式、实地址模式(简称实模式)、系统管理模式和虚拟8086模式
我们在操作系统实验过程中仅用到实模式和保护模式
IA-32处理器有8个通用寄存器eax, ebx, ecx, edx, ebp, esp, esi, edi
除此之外,还有6个段寄存器cs, ss, ds, es, fs, gs
以及标志寄存器eflags和指令寄存器eip
更多的寄存器
后面的实验中,还会遇到更多寄存器,比如开启保护模式需要用到的cr0,存储页目录表基地址的cr3、存储产生缺页错误的地址的寄存器cr2等
但是目前暂时只需要使用到上面的寄存器
在nasm中,除了可以直接使用上述的名字访问寄存器的全部内容,还提供了访问部分寄存器低位数据的访问方式:
| [31:0] | [15:0] | [15:8] | [7:0] |
|---|---|---|---|
eax |
ax |
ah |
al |
ebx |
bx |
bh |
bl |
ecx |
cx |
ch |
cl |
edx |
dx |
dh |
dl |
esi |
si |
– | – |
edi |
di |
– | – |
esp |
sp |
– | – |
ebp |
bp |
– | – |
同时,nasm还有一套约定俗成的规矩,用来指定寄存器的作用
其中,有一些规定是被 默认使用 的:
| 寄存器 | 作用 |
|---|---|
eax |
在乘法和除法指令中被自动使用 同时也用做返回值寄存器, C或C++函数的返回值放置在eax中 |
ecx |
在循环 (loop) 指令中被默认为计数器 也即将循环次数存储在 ecx中,loop指令只有当ecx为0时停止 |
esp |
在对栈进行push和pop操作时,会自动从esp中取基地址也即 push eax实际上相当于sub esp, 4,mov eax, [esp] |
esi, edi |
用于内存数据高速传送,本次实验中用不到 |
ebp |
通常用于在栈上取数据时使用,一般不用于算数或是数据传输 后续 C++与asm混编后会经常遇到关于ebp的内容 |
cs |
16位代码段寄存器 |
ds |
16位数据段寄存器 |
ss |
16位栈段寄存器 |
还有一些类似于习惯的规定,似乎不遵守它们也不会让程序出现错误:
| 寄存器 | 作用 |
|---|---|
eax |
一般用于算数运算 比如 add eax, 4,因而也叫做累加寄存器 |
ebx |
基地址寄存器,用于在取址时提供基地址 比如 mov eax, dword [ebx + 2]为取出ebx + 2位置上32位的数据放入eax |
edx |
数据寄存器 |
esi |
源变址寄存器,用于在取值时提供偏移的地址 比如 mov eax, dword [ebx + esi + 2]或是mov eax, dword [esi + 2] |
edi |
目的变址寄存器,用于在取值时提供偏移的地址 比如 mov dword [edi + 2], eax |
es, fs, gs |
16位附加段寄存器,用来存放其他的段 |
寻址
基地址寄存器和变址寄存器涉及到 寻址 相关的内容,可以前往寻址页面查看
段寄存器
段寄存器涉及到 保护模式 相关的内容,可以前往基本概念查看
标识符是我们取的名字,用来表示变量、常量、过程、函数或代码标号
标识符满足如下要求和特性:
- 至少1个字符,最多247个字符
- 大小写不敏感
- 第一个字符必须是字母、
_或是@,后续字符可以包含数字 - 不能与保留字相同
下面是一些有效的标识符
1 | var1 |
下面是一些使用标识符的示例
1 | ; Function |
标号是充当指令或数据位置标记的标识符,可以直接将其理解为一个地址值,指向的是其之后指令或是数据的起始地址
例如
1 | count dw 100 |
中count指向的就是其之后4字节长度的数据100的起始地址
如果有更长的数据,则可以这样写
1 | pgdt dw 0 |
在.asm文件中,可以视为地址是从第一行代码向下增长的
这样写相当于声明了一个值为0x880000000000的数据
其低4字节为dw 0所声明的值,高2字节为dd 0x8800声明的值
而pgdt指向其低四字节的起始地址,也即该数据最低字节的地址
IA-32为小端序
在实验中使用的IA-32处理器所使用的是小端序 (little-endian)
这意味着数据的低位被放在低地址处而高位被放在高地址处
对于一个多字节的数据,其标识符指向的是它的最低字节数据地址
标号也可以用于声明相当于C语言中数组的数据项
数据项之间以,分隔,标号指向第一个数据项最低字节的地址
1 | array dw 1024, 2048 |
上述代码按照1024,2048,4096,8192的顺序存放数据,同时array指向1024
标号也可以用来在过程中添加标记以方便跳转
1 | Stage_1: |
这里,Stage_1并不会编译成汇编代码,而是会编译为mov eax, ebx这一步的地址值,jmp Stage_1相当于跳转到mov eax, ebx这句执行
标号后面的换行和空格并不会影响标号的值
也就是说Stage_1: mov eax, ebx中Stage_1跟上面的代码拥有一样的标号值
如何理解寻址
寻址可以理解为代码获得某个数据的方式
例如,寄存器寻址 可以理解为代码通过寄存器获得数据
nasm有六种寻址方式,分别为
-
寄存器寻址:操作数存放在寄存器中,从寄存器中取得数据
1
mov eax, ebx ; eax = ebx
-
立即数寻址:直接将立即数作为操作数
1
mov eax, 0x20 ; eax = 0x20
-
直接寻址:从立即数或是标号指向的地址处取得数据
从立即数指向的地址取得数据
1
2
3
4
5
6; 从0x5C00处取得数据
;
; 相当于C语言中
; uint32* ptr = (uint32*)0x5C00;
; eax = *ptr
mov eax, dword [0x5C00]也可以从标号指向的地址取得数据
1
2tag dw 0x20
mov eax, dword [tag] ; eax = 0x20 -
基址寻址:将基址寄存器所储存的数值视为地址并从该地址处取得数据
基址寻址类似于数组的寻址,基址寄存器只能是寄存器
bx或bp1
2
3tag dw 0x20
mov ebx, tag ; ebx中存储的是tag的值,也就是0x20的地址
mov eax, dword [ebx] ; eax = 0x20基址寻址也可以使用基址寄存器和立即数来构成真实的偏移地址
1
2
3
4
5
6tag dw 0x20
; 构造一个与tag对应的地址差4的地址存入ebx
mov ecx, tag
sub ecx, 4
mov ebx, ecx
mov eax, dword [ebx + 4] ; eax = 0x20 -
变址寻址:使用变址寄存器和立即数来构成真实的偏移地址,从该地址处取得数据
变址寻址与基址寻址相似,变址寄存器只能是
si或di1
2mov eax, dword [esi + 4 * 4] ; eax = *(uint32*)(esi + 4 * 4)
mov dword [edi], 0x5 ; *(uint32*)edi = 0x5 -
基址变址寻址:通过基址寄存器、变址寄存器、立即数来构成真实的偏移地址,从该地址处取得数据
1
mov eax, dword [ebx + esi + 4 * 5] ; eax = *(uint32*)(ebx + esi + 4 * 5)
不够用的地址?
在 实模式 下,IA-32处理器使用 20位 的地址线
不难发现在这种情况下可以访问的内存范围为,范围从0x0000到0xFFFF
但是寄存器只有 16位,意味着使用基址、变址寻址的时候没办法访问到所有的内存地址
为了解决这个问题,工程师提出了 段 的概念,使用了段地址之后,实际的地址可以表示为
也就是物理地址由左移4位的段地址加上偏移地址组成,这个偏移地址就由标号或是寄存器提供
此段非彼段
目前我们讨论的是 实模式 下的问题,此时的段是用来解决寄存器不足以访问所有的内存地址的问题
在后面的 保护模式 中,还将看到另一个段定义,它与本节所述的段并不是同一个概念
段地址的使用一般出现在使用[]来寻址的操作中,因为在这种情况下[]内表示的是一个地址,而这个地址很可能由一个16位的寄存器或是标号提供
添加了段地址的寻址语法为
1 | mov ax, word [ds:bx] |
在默认的情况下,系统会根据使用的标号和寄存器自动指定段地址,指定的段地址与使用的基址寄存器有直接关系
由于这里讨论的是实模式,所以只讨论16位寄存器
对于bx、si、di,默认的段寄存器为ds
对于bp,默认的段寄存器为ss
对于基址变址寻址方式,默认的段寄存器以基址寄存器的使用为准
1 | ; 下面的语句等价 |
下文中可能用到的标识符解释如下
| 标识符 | 意义 |
|---|---|
| reg | 寄存器 |
| imm | 立即数 |
| immX | X位立即数 |
| tag | 标号 |
| mem | 使用寻址方式取得的内存数据,例如[ebx] |
1 | ; Syntax |
1 | ; Syntax |
imul完成整数乘法操作
1 | ; Syntax |
idiv完成整数除法操作
idiv只有一个操作数,此操作数为除数,而被除数则为edx:eax中的内容 (一个64位的整数)
操作的结果有两个部分
- 商:存放在
eax寄存器中 - 余数:存放在
edx寄存器中
1 | ; Syntax |
shl,shr表示逻辑左移和逻辑右移,空出的位补0
1 | ; Syntax |
inc,dec指令分别表示自增1或自减1
1 | ; Syntax |
and, or, xor分别表示将两个操作数逻辑与、逻辑或和逻辑异或后放入到第一个操作数中
1 | ; Syntax |
not表示对操作数每一位取反,neg表示对操作数取负
1 | ; Syntax |
jmp指令是无条件跳转指令,跳转到代码标号的指令处执行
1 | ; Syntax |
除了无条件跳转指令外,还有条件跳转指令
1 | je <tag> ; jump when equal |
在使用条件跳转指令之前,要先进行判断,判断使用的是cmp指令
1 | ; Syntax |
一个条件跳转的示例如下,其展示了一个不适用loop指令循环10次的简单实现
1 | xor eax, eax |
push和pop为栈操作,负责将寄存器值压栈、弹栈
in、out为端口读写操作,它们的操作数非常严格
1 | ; Syntax |
其中,al/ax/eax根据端口位宽设置,如果对8位端口指定了16位输入/输出,则会连带该端口的下一个端口一并进行输入/输出
基本概念
本页的内容基于OSDev Wiki关于实模式的介绍
实模式是所有的x86处理器都有的一个16位运行模式
这个模式是为早期的操作系统设计的,它的出现远远早于保护模式
即使现在的操作系统已经运行在保护模式下了,但是处于兼容性考虑,所有的现代操作系统都需要先从实模式开始运行,然后再切换到保护模式
在实模式下,CPU只有20根地址线可用,也即可用内存为
为了让16位寄存器能够对全部内存地址空间进行取址,额外引入了段寄存器cs、ss、ds和es、fs、gs,地址的表示由段地址和寄存器表示的偏移地址组合而成
段地址保存在段寄存器中,其中es、fs和gs为附加段寄存器,可以由用户自行指定
本页的内容基于OSDev Wiki关于保护模式的介绍
保护模式是目前英特尔处理器主流的运行模式,在保护模式中,处理器以32位模式运行,所有的寄存器也都为32位
为了进入保护模式,操作系统需要在实模式下进行一系列操作:
- 设置全局描述符表
- 关闭中断
- 开启第21根地址线
- 打开保护模式开关
- 执行一次远跳转送入代码段选择子
具体的切换方式让我们留到实验中再行讲解
保护模式之所以叫做保护模式,因为其引入了 “段” 的概念,每一个程序都有它自己的段,一旦程序错误地访问其他段的地址空间,那么CPU就会产生异常
段 (segment)
段实际上是程序员人为划分的一块块连续的内存区域,或者称为地址空间
误区
这里的段概念与实模式的段概念并不相同
也就是说,可以认为保护模式保护的是地址空间,防止程序代码错误地访问了非它自己的段地址空间,造成越界访问
为了让CPU知道段的范围,工程师引入了全局描述符表的概念
全局描述符表可以理解为一段连续的内存,类似于数组,其中存储了全局描述符,每个描述符都对应了一个段的设置
为了取出对应的全局描述符,就如同用下标从数组中获取数据那样,CPU使用选择子从全局描述符表中获取描述符
选择子除了包含了取出描述符所需要的下标信息,还包含了一些权限信息等,这些选择子会被存储在段寄存器中
更多的保护内容
除了段保护之外,保护模式实际上还包括了特权级的保护、页保护等
例如,保护模式会阻值低特权级代码访问高特权级段空间,会依据特权级限制程序操作等
操作系统是由中断驱动的
操作系统的最终目的是完成用户的任务,但很显然,用户不会时时刻刻都有需要操作系统完成的任务,同时,当用户没有向操作系统提交任务的时候,它应当去干点别的而不是傻傻地待在原地等着用户提交任务——这也就是中断的意义
可以把操作系统想象成一个忙碌的打工人,当你向他提交了任务以后,他便会开始完成你提交的任务。但如果在他进行到一半的时候,你突然又想让他干点别的,该怎么办呢?对了!就是拍拍他的肩膀,说:“伙计,先停停手上的活,把这件事情做了,然后再回来做现在的活儿。”
中断对于操作系统的作用也正是这样,通过中断,可以让CPU暂停当前正在运行的代码,转而对产生中断的信息进行处理,当处理完后再返回运行原先的代码
通过中断,可以让操作系统在等待用户/内核打断的同时进行其他的任务,而不需要在原地循环等待用户的下一步指令
又由于操作系统实质就是无数个 中断-处理-返回 的过程,所以可以说这就是操作系统进行任务的最根本方式,所有的操作都要经由中断来实施,所以可以说 “操作系统是由中断驱动的”
实验路线
第零阶段:知识准备
环境搭建
在这一步中,需要搭建实验所必需的Linux环境以及虚拟机qemu和C、C++、asm编译器等
如果读完了 操作系统日志 第一章 的话,那么这一步已经完成了
汇编语法与操作系统概念
由于实验的第一部分 ( 编写MBR ) 就需要使用到汇编语法,因此首先需要了解的就是nasm汇编语法
其次,为了能够对实验有整体的把握,建议先完整阅读 《 操作系统概念(第九版)》 对操作系统有一个整体视角再着手开始实验,这样更有利于落实自己的想法并体验到实验的乐趣所在
当然,如果是正在跟随课程实验进行,尚不能提前通读整本书的话,也不要担心,因为随着实验的进行也是完全能够循序渐进地认识操作系统的各个概念的
如果阅读了前文的 前序知识 的话,那么就已经足够可以让我们编写MBR了,让我们继续吧
第一阶段:启动Kernel
MBR
本节需要完成:
- 使用 中断 加载
bootloader - 跳转到
bootloader运行
bootloader
本节需要完成:
- 切换到 保护模式
- 从磁盘加载
kernelloader - 跳转到
kernelloader运行
准备
从这一节开始,将会从asm编程切换到C++和内联汇编组合编程
为了能够使得操作系统能够方便地组织和使用硬件资源,需要对硬件的接口进行 抽象,编写合适的 驱动
同时,为了加强代码的可读性,需要将常用的结构包装为 类
驱动的编写和结构的封装并不需要在这一步就全部完成,而是随着后续代码的编写而逐渐完善
为了后续实验顺利进行,在这一步需要完成如下驱动:
- 端口驱动
UART驱动- 磁盘驱动
- 显示驱动
同时需要完成如下结构体:
pagetable:页表page:页frame:帧elf head:ELF头
kernelloader
本节需要完成:
- 开启 分页机制
- 装载 文件系统
- 编写
elf parser - 从文件系统中读取
kernel.o - 使用
elf parser解析kernel.o中的 ELF头 并加载内核入内存正确地址处 - 跳转到内核运行
想要支持多系统?
在linux的实现中,多系统通过grub提供引导,关于grub的更多信息可以查看 GNU GRUB的Wiki页面
第二阶段:内核态
堆分配器
实现malloc和free
从此节开始后,将可以使用malloc和free函数
这也意味着同样也可以使用vector等等各种数据结构了,代码的编写自此进入现代化
页帧分配器
实现 物理页帧 的管理和分配
虚拟页管理器
实现 虚拟页 的管理和分配,实现 虚拟页到物理页的映射
描述符表
实现GDT、IDT和TSS的抽象,并初始化描述符表
中断
实现 中断处理函数
本节中会涉及部分用户进程的知识
由于用户进程和内核进程都需要使用中断,同时用户进程和内核进程进入中断时在栈上的行为还天杀的不一样
为了避免反复编写重复代码,会提前介绍用户进程的行为以及如何编写代码解决其中的问题
内核进程
实现 内核进程 以及 进程管理器
完成本节后,就有了进程调度机制,可以支持并发了
第三阶段:用户态
系统调用
由于用户进程不能直接运行内核相关的代码,因此需要实现系统调用来在对用户进程透明的情况下执行内核相关代码
用户进程
在完成系统调用之后,就可以实现 用户进程 了
Shell
实现一个 Shell 程序提供用户交互
从MBR开始编写自己的操作系统
真正的实验从这里开始
创建项目
首先给项目创建一个仓库,不妨叫做MyOS
之后,为项目创建一个编译用文件夹build,一个存放镜像文件的文件夹run,一个存放所有代码的文件夹src
由于目前我们需要完成的是操作系统启动的部分,因此本节的代码mbr.asm放置在src/boot文件夹下,同时,为了能够方便地编译项目,在build文件夹下创建项目的makefile文件
创建完成之后的项目目录看起来就像这样
1 | . |
Hello World
Hello World实验作为各大语言的必经之路,在操统实验中自然也是必不可少的
在尝试输出代码之前,先研究一下怎样让操作系统显示出我们想要的东西…
通过显存显示内容
qemu显示屏实际上是按25x80个字符来排列的矩阵,如下所示
为了便于控制显示的内容,IA-32处理器将这个矩阵映射到了内存地址的0xB8000~0xBFFFF处,这段地址被称为显存地址
在文本模式下,控制器的最小可控制单位为字符。每一个显示字符自上而下,从左到右依次使用显存中的两个字节表示,低字节表示显示的字符,高字节表示字符的颜色属性。
例如,黑底白字的H在显存中如下存放:
| 显存地址 | 值 | 含义 |
|---|---|---|
| … | - | - |
| B800:0001 | 0x0F | 背景色黑色,前景色白色 |
| B800:0000 | 0x48 | 字符H |
每个字符的颜色又由两部分组成,高4位为字符的背景色,低4位为字符的前景色,每个颜色由R、G、B和K/I位组成
K/I位含义如下
| K/I | 背景色 | 前景色 |
|---|---|---|
| 0 | 不闪烁 | 深色 |
| 1 | 闪烁 | 亮(浅)色 |
字符颜色的对照表如下
| R | G | B | 颜色 |
|---|---|---|---|
| 0 | 0 | 0 | 黑色 |
| 0 | 0 | 1 | 蓝色 |
| 0 | 1 | 0 | 绿色 |
| 0 | 1 | 1 | 青色 |
| 1 | 0 | 0 | 红色 |
| 1 | 0 | 1 | 品红 |
| 1 | 1 | 0 | 棕色 |
| 1 | 1 | 1 | 白色 |
也就是说,0x0F对应的是 背景色为黑色不闪烁,前景色为亮白色的颜色
于是,记 为第 行 列,如果想要在 处显示一个字符,则需要做
- 计算出该坐标相对于显存起始地址的偏移量
- 获得字符的颜色值
- 将字符ASCII码和颜色值放置在显存中
其中,由于一行有80列,每个字符占用两个字节的空间,因此偏移地址计算的公式如下
之所以要用偏移地址,是因为很容易发现,0xB8000这一个起始地址已经超出了16位所能表示的范围,因此需要引入段地址,这里再回顾一次引用段地址后实际地址的计算公式:
很显然,将段地址设置为0xB800可以让偏移地址从0x0开始取值,因此不妨将段地址0xB800放置在附加段寄存器gs中,然后使用[gs:index]格式进行取址,例如
1 | mov byte [gs:0], 'H' |
就是将黑底白字的H显示在坐标 处
通过中断显示内容
除了使用显存赋值这一操作来显示字符,在实模式下还提供了另一种显示字符的方式——中断
中断的调用涉及了四个部分:
- 设置中断参数:参数一般为存储在
bx、cx和dx寄存器或是它们的高低位中的值 - 设置中断功能:一种中断调用可以实现很多不同的功能,具体要调用的功能一般通过
ax或是ah指定 - 调用中断:使用
int指令和对应的中断向量号调用中断 - 获取返回值:中断函数如果有返回值的话一般是放在寄存器中,所以要从寄存器中获取返回值
BIOS提供了很多中断函数,中断向量号和它们的功能可以查看 OSDev Wiki中关于BIOS的页面
在本次实验中我们暂时只关注int 10h这个函数,它提供了光标相关的操作,对应的参数和返回值可以参考 Wikipedia 中关于光标中断的页面
为了方便查阅,显示字符所需要用到功能在下表列出
| 功能 | 功能号 | 参数 | 返回值 |
|---|---|---|---|
| 设置光标位置 | AH=02H |
BH:页码DH:行,DL:列 |
- |
| 获取光标位置 | AH=03H |
BX:页码 |
AX=0CH:行扫描开始,CL:行扫描结束DH:行,DL:列实验中一般只需要用到 DH和DL |
| 在光标位置写入字符 | AH=09H |
AL:字符,BL:颜色BH:页码,CX:输出字符个数 |
- |
所以在 处写入字符需要如下步骤:
- 设置光标位置为 行 列
- 设置字符颜色等参数
- 在光标位置写入字符
例如,在 处写入黑底白色的字符H操作为
1 | move_cursor: |
编写MBR
回顾:MBR的加载
计算机加电启动并完成自检之后,BIOS会根据引导顺序检查磁盘首扇区 (也即存放MBR的扇区) 是否可以启动
如果可以启动,BIOS会将这512字节加载到0x7C00处开始执行
此时,CPU运行在 实模式 下
为了让编译器能够正确理解 “我们是在编写MBR” 这件事,需要使用一些汇编的伪指令告知编译器:
- 代码会被加载到
0x7C00处执行 - 代码在16位模式下运行
翻译成asm语言如下
1 | [org 0x7C00] |
之后,需要对寄存器进行初始化,避免为初始化的段地址影响后续的取址操作
需要注意的是,段寄存器只能通过ax寄存器赋值,所以可以先将ax置0,然后再通过ax将段寄存器置0
陷阱:不要初始化cs
在初始化段寄存器的时候,通过实验发现,ds, ss, es, fs, gs都可以正常进行置0操作
但是如果对cs进行置0,则会导致代码出现意料之外的行为
所以不要将cs寄存器初始化
1 | ; Initialize registers |
此时栈指针寄存器sp还没有被初始化,由于栈是从高地址向低地址增长的,所以需要给栈分配一段可以向下增长的空间
这一段空间的选择相对自由,但是由于MBR对栈空间的使用较小,并且当启动到后续阶段的时候也可以再移动栈指针,所以不妨将栈指针放置在0x7C00处让其向下增长
1 | ; Initialize stack pointer |
之后使用显存显示内容的方式来完成Hello World!字串的输出
1 | ; Print something |
陷阱:不要将数据放置在代码中间或者前部
BIOS从0x7C00处开始执行代码,其并不区分内存中存储的二进制码究竟是数据还是指令,因此如果将数据放置在代码前面,可能会让CPU误认为数据是代码从而被执行,产生无法预料的错误,这类错误往往很难通过调试发现
不要让代码掉进 “虚无”
可以在代码后面添加jmp $,其中$的意思是当前语句的地址,这句指令无限跳转到其自身执行
这阻止了CPU继续执行这句代码之后的内容,因为后面可能是数据空间或是虚无,它们同样可能被解读成错误的指令从而产生无法预料的错误
最后,由于还没有开始做文件系统和磁盘分区,不妨将MBR后续字节填充零,使用伪指令times来重复填充,$ - $$很容易解读出其意译为当前地址减去文件起始地址的差
1 | ; Fill 0 before byte 447 |
完整的mbr.asm文件如下
1 | [org 0x7C00] ; Indicates codes below starts at 0x7C00 |
编写makefile
Makefile Tutorial
如果对Makefile语法尚不熟悉,可以前往 Makefile Tutorial 页面了解
为了让项目能够顺利地运行起来,需要编写Makefile文件。在默认已经了解Makefile语法的前提下,简要介绍从MBR启动所需要的各个文件以及它们的依赖关系
| 文件 | 作用 | 依赖关系 |
|---|---|---|
hd.img |
硬盘文件 QEMU会尝试从这个文件的首扇区加载MBR启动 |
mbr.bin需要将MBR写入磁盘才能够启动 |
mbr.bin |
MBR编译后的二进制文件 | mbr.asm |
mbr.asm |
MBR源文件 | - |
根据这些依赖关系,可以写出Makefile文件
1 | ASM_COMPILER := nasm |
运行和结果
进入项目目录下的build/目录
1 | make clean build run |
可以首先清除原先生成的文件,重新构建并且运行
运行的结果如下
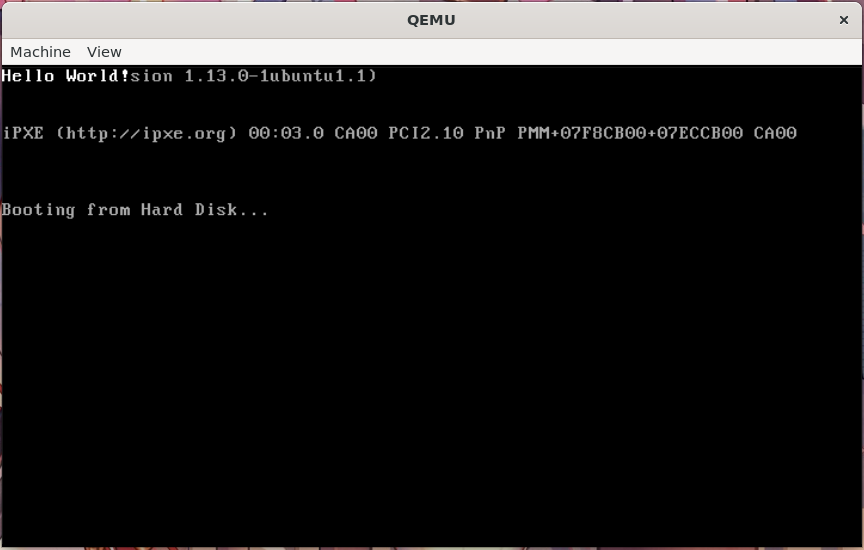
完成本章
下一章中,将会编写bootloader,从mbr中加载bootloader并且启动,最后在bootloader中让CPU进入保护模式
如果准备好了的话,就让我们进入下一章吧!
