操统实验日志 第三章 从实模式到保护模式
关于本章
在本章的第一部分中,将会介绍读取硬盘的CHS方式、LBA方式以及如何通过in、out指令读写硬盘,之后会将上一章输出Hello World!的代码移植到BootLoader中,并且从MBR中加载并跳转到编写的BootLoader执行
在第二部分中,会回顾保护模式的概念并介绍进入保护模式的四个步骤,并在开启保护模式之后输出第二个Hello World
第一次跃进:从MBR跳转到BootLoader
MBR只有512字节的大小,甚至如果除去分区表,只有四百多字节的大小,这个大小稍微复杂一些的程序就难以运行了,更不要说是把全部的操作系统都放在里面了
因此,目前的首要任务就是 突破512字节的限制,从而能够让我们着手编写更复杂的程序,其实,聪明的工程师很早就提出了一个可行的解决方案:在MBR里面把另一段更大的程序加载到内存里面,之后跳转到加载的地址去执行,这个 “更大的程序” 就是我们本节要编写的BootLoader,它在编译之后会被烧录到硬盘镜像中指定的扇区里,MBR要做的事情就是从这些扇区里面把我们编写的BootLoader加载出来放在内存里,然后跳转到加载的内存地址处执行BootLoader的代码
为什么不直接从MBR跳转到内核运行?
从上一章的实验路线中可以看到,在加载内核之前有许多需要准备的工作,包括开启虚拟分页机制以及文件系统的装载
很显然这些并不能在MBR中完成,所以需要在MBR和内核中间添加一些步骤,作为启动内核前的准备操作
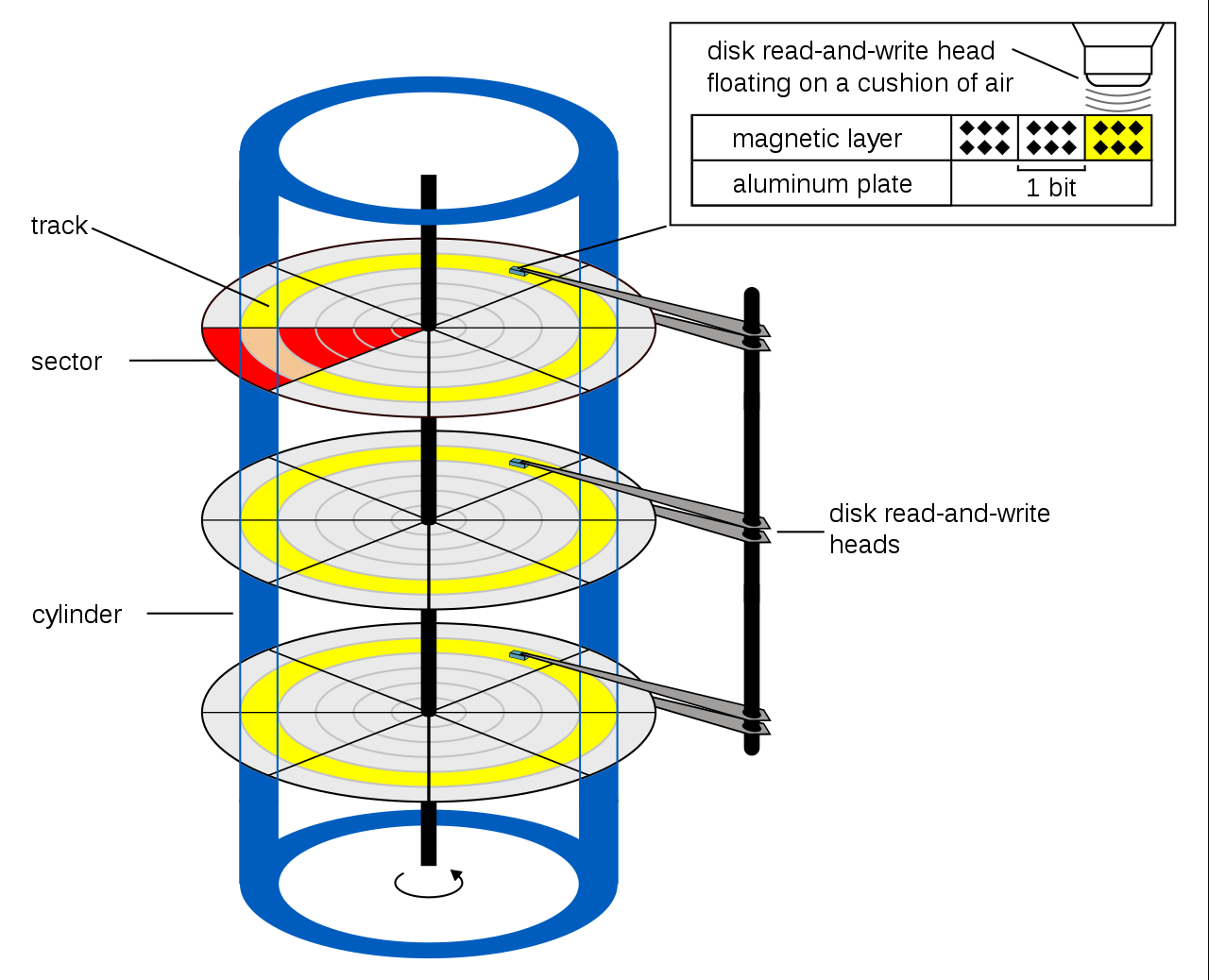
简述CHS模式
CHS全称为 Cylinder-head-sector,是早期用来定位硬盘上扇区的一种方式
在CHS中,扇区通过不同的 柱面 (Cylinder)、磁头 (Head) 和 扇区 (Sector) 指定,除此之外,在CHS中还有一个额外的概念 磁道 (Track) ,下面简要介绍这四个概念的含义
-
柱面:
磁盘是由很多层碟片堆叠而成的,可以想象为一个实心的圆柱体。如果用一个与磁盘同心的空心圆柱去切割 (或者说做相交的操作),则每一个磁盘都会被相交得到一个空心圆,这些空心圆的组合就叫做柱面,实际上,它们看起来也确实像一个圆柱的外表面,而这个圆柱与做相交时的空心圆柱大小是一样的换一种说法,每一个碟片都是由很多个同心圆组成的,这些同心圆被叫做 磁道,从外到内由0开始编号,每个碟片上的磁道数都是相同而且对齐的,也就是说,如果我们俯视一个磁盘,那么最上面的碟片的磁道是怎么分布的,它下面的碟片也都是这么分布的,如果我们对所有碟片选定同一个磁道,那么它从上到下看起来就会构成一个圆柱的外表面,也就是 柱面,这个磁道编号就是柱面号
-
磁头:
一个磁盘有很多个碟片,对应地,每个碟片也有一个磁头用来读写数据,磁头从上往下由0开始编号,这个编号就是磁头号。一般来说,磁头会停留在一个同心圆 (也就是磁道) 上,并且可以在不同的磁道间移动 -
扇区
磁盘的每一个扇区都可以按照旋转角度被等分为很多段圆弧,每一段圆弧就被称作一个扇区,扇区大小一般为512字节扇区与数据密度
很容易发现,如果对整个碟片上所有的磁道都按照一个单一的旋转角度来划分扇区,则每个扇区虽然对应的圆心角相同、数据容量相同,但是长度却不一样,这就会让外圈的磁道数据密度降低
事实上,老式的磁盘使用的就是这种方式,确实会导致内外磁道数据密度不同的问题
而目前有新的解决方式按照等密度的方式划分扇区,也就是越靠外的磁道扇区数越多在实验中将使用经典的理解,也就是老式磁盘的划分方式,同时后面也会看到在LBA模式中这种差异将不会对取址产生影响
-
磁道:
每一个碟片都是由很多个同心圆组成的,这些同心圆被叫做 磁道。同时,磁道也可以理解为是由柱面和磁头对应的盘面相交得到的圆也就是说,一个柱面和一个磁头可以唯一指定一个磁道,在CHS取址模式中不需要提供磁道号也正是这个原因
如果还不能够完全理解,可以查看Wikipedia关于CHS模式的页面中精妙的配图如下
简述LBA模式
LBA模式全称为 Logical Block Addressing,顾名思义,就是通过逻辑扇区号去寻址物理扇区号,具体的寻址方式则是对用户透明的
在LBA模式下,不存在像CHS那样复杂的概念,硬盘的扇区被看作是线性的并从0扇区开始编号,当使用LBA扇区号进行取址的时候,存储设备会自动转换成对应的柱面、磁头和扇区进行读取,用户不需要关心这部分的实现
陷阱:CHS和LBA模式的扇区编号不同
在CHS模式下,扇区从1开始编号,而在LBA模式下,扇区从0开始编号
通过CHS编号来计算LBA编号可以使用如下公式,其中HPC为柱面中的磁头数 Heads per Cylinder,SPT为每个磁道中的扇区数 Sectors per Track
同样,LBA模式也可以通过下述公式转换为CHS编号
在LBA模式下通过端口读写磁盘
接口和模式
在实验中使用的接口为ATA,使用PIO模式进行访问
ATA PIO模式
ATA PIO mode的更多信息可以查看OSDev中关于这一主题的页面
ATA、PATA、SATA的区别
关于ATA、PATA、SATA以及ATA PIO之间的区别,可以查看Reddit中关于这个主题的讨论
了解了硬盘的寻址模式之后,就可以开始着手从磁盘里读取数据了,在实验中我就采用了更为 无脑 简单的LBA28模式
LBA28
LBA28指的是使用28位来表示逻辑扇区的编号
既然要从磁盘读取数据,那就自然要告诉磁盘 读数据、去哪读和读多少,端口就在这个过程中充当了信使的角色,我们通过向端口发送数据,告诉磁盘读取地址和读取数量,等候磁盘完成后再从端口接收数据
在磁盘读的操作中,要用到的端口及其描述如下
| 端口号 | 端口数据传输方向 | 作用 (LBA28) | 描述 | 位长 (LBA28) |
|---|---|---|---|---|
| 0x1F0 | 读/写 | 数据寄存器 | 硬盘读出/要写入的数据 | 16-bit |
| 0x1F1 | 读 | 错误码寄存器 | 存储执行的ATA指令所产生的错误码 | 8-bit |
| 0x1F1 | 写 | 功能寄存器 | 用来指定特定指令的接口功能 | 8-bit |
| 0x1F2 | 读/写 | 扇区数寄存器 | 存放需要读写的扇区数量 | 8-bit |
| 0x1F3 | 读/写 | 起始扇区寄存器 | 存放起始扇区0-7位 | 8-bit |
| 0x1F4 | 读/写 | 起始扇区寄存器 | 存放起始扇区8-15位 | 8-bit |
| 0x1F5 | 读/写 | 起始扇区寄存器 | 存放起始扇区16-23位 | 8-bit |
| 0x1F6 | 读/写 | 磁盘、起始扇区寄存器 | 选择磁盘和访问模式 存放起始扇区24-27位 |
8-bit |
| 0x1F7 | 读 | 状态寄存器 | 读取当前磁盘状态 | 8-bit |
| 0x1F7 | 写 | 指令寄存器 | 传送ATA指令 | 8-bit |
其中,部分端口的位作用比较复杂,部分位在实验中也不需要留意,使用*号注明
| 端口号 | 位 | 缩写 | 作用 |
|---|---|---|---|
| 0x1F6 | 0-3 | - | 在LBA模式中,指定其起始扇区号的24-27位 |
| 0x1F6 | 4 | DRV | 指定磁盘0:主硬盘1:从硬盘 |
| 0x1F6 | 5 | 1 | 始终置位 |
| 0x1F6 | 6 | LBA | 指定访问模式0:CHS模式1:LBA模式 |
| 0x1F6 | 7 | 1 | 始终置位 |
| 端口号 | 位 | 缩写 | 作用 |
|---|---|---|---|
| 0x1F7 (Read) | 0 | ERR | 指示是否有错误发生,通过发送新指令可以清除该位 |
| 0x1F7 (Read) | 1* | IDX | 索引,始终置为0 |
| 0x1F7 (Read) | 2* | CORR | 修正数据,始终置位0 |
| 0x1F7 (Read) | 3 | DRQ | 0:硬盘还不能交换数据1:硬盘存在可以读取的数据或是可以写入数据 |
| 0x1F7 (Read) | 4* | SRV | 重叠模式服务请求 |
| 0x1F7 (Read) | 5* | DF | 驱动器故障错误 |
| 0x1F7 (Read) | 6* | RDY | 0:驱动器发生了减速或是错误1:驱动器运转正常 |
| 0x1F7 (Read) | 7 | BSY | 忙位0:空闲1:忙 |
了解了各个端口的作用后,如何从硬盘读取数据似乎就是显而易见的了:
- 设置起始扇区号
- 设置读取的扇区数量
- 设置磁盘和访问模式
- 检测状态位,等待硬盘就绪
- 从端口读取数据
为了方便代码重用 (虽然MBR的代码也不会重用了),在实验中将读取硬盘的功能包装成一个汇编函数进行调用
NASM中的函数调用
调用函数前,通过将参数压栈的方式传递参数
使用call tag调用函数,在执行call指令时会将下一条指令地址压入栈顶
在函数内部,需要使用pushad为主调函数保存寄存器的值
在函数结束后,使用ret返回,在执行ret指令时会取出栈顶值并跳转到该值处执行
调用函数后,通过执行add sp, <imm>操作将栈指针上移,从栈上删除传递的参数
令函数名为read_sectors,并假定主调函数向其传递四个参数值startSector[15:0]、startSector[27:16]、sectorCount和targetAddress,可以据此先写出函数体
1 | read_sectors: |
之后从栈上依次取出起始扇区号并发送到端口0x1F3~0x1F6
陷阱:注意正确设置0x1F6端口高4位
0x1F6端口高四位包括了主从硬盘位和访问模式位
如果误使用CHS模式读取硬盘,由于CHS扇区从1开始编号,会导致读出错误的扇区
陷阱:栈上的字长为2字节
在16位模式中栈上的字长为2字节,因此使用bp在栈上取数据时步进为2而不是4
也就是,如果使用上文中的函数开头,第一个参数的为word [bp + 2 * 2]
1 | mov bx, word [bp + 2 * 2] ; bx = startSector[15:0] |
然后通过0x1F2端口设置读取的扇区数量
1 | mov al, byte [bp + 4 * 2] ; al = sectorCount |
向0x1F7端口发送0x20指令请求硬盘读
1 | mov dx, 0x1F7 |
在发送读请求后,通过循环检测0x1F7端口的0、3、7位等待硬盘就绪,就绪的标志为这三位依次为0、1、0
陷阱:记得等待硬盘就绪
在从端口读取数据前,一定要等待硬盘就绪,不然会读出错误的数据
1 | .wait_disk: |
最后,从0x1F0端口读取数据
0x1F0端口为16位端口,因此一次可以读取两个字节,总的读取次数为
1 | xor ax, ax ; Set ax = 0 |
所以完整的读取函数为
1 | ; Loader sector function |
加载BootLoader并跳转
为了验证上一节中读取硬盘函数的正确性,现在需要在项目中创建BootLoader,由于目前我们还不打算在BootLoader中完成很复杂的任务,所以就先将上一节中打印’Hello World!'的代码移植到BootLoader中,然后尝试从MBR加载并跳转到BootLoader执行,看看能否正常运行
首先我们需要扩充我们的项目结构:
- BootLoader自身需要一个汇编文件
bootloader.asm,由于它同样属于启动过程,所以可以将它放置在/src/boot/目录下 - 由于BootLoader加载需要指定 起始扇区号、扇区数量 和 加载地址,为了方便修改,增加代码可读性,可以像C语言那样将这些数值定义为常数值放在头文件中,然后在代码中引用这个头文件。于是我们为启动过程添加一个共同的头文件
boot.inc,用于指定启动过程中用到的所有常数值,这个文件同样放置在/src/boot/目录下
扩充后的项目结构大致像这样
1 | . |
在开始移植之前,需要先确认BootLoader的起始地址以及它的大小,这涉及到内存地址的安排
在操作系统内核设计的过程中,内存规划是一件令人苦恼的事情,但同时也是一件自由的事情,只要不发生溢出和重叠之类的问题,将内容放置在哪里是一个相对主观的事情
这里我将BootLoader直接放置在MBR后面,占用4个扇区的大小,内存的安排如下
| 用途 | 起始地址 | 终止地址 | 扇区数 |
|---|---|---|---|
| MBR | 0x7C00 | 0x7E00 | 1 |
| BootLoader | 0x7E00 | 0x8600 | 4 |
完成了内存规划之后,就可以将常数写入头文件中了
1 | ; Constants used during the boot procedure |
打印Hello World!代码的移植步骤就比较简单了,直接复制粘贴入bootloader.asm即可,不过需要注意的是要修改一下头部伪代码中的[org 0x7C00]为BootLoader的起始地址[org 0x7E00]
1 | "boot.inc" |
之后,对mbr.asm中的代码进行修改
向其中添加read_sectors函数并且调用read_sectors函数
1 | ; Read bootloader |
跳转到BootLoader的起始地址
1 | ; Jump to bootloader |
最后,修改makefile文件,由于添加了两个文件,依赖关系也产生了变化,新的依赖关系如下
| 文件 | 作用 | 依赖关系 |
|---|---|---|
hd.img |
硬盘文件 QEMU会尝试从这个文件的首扇区加载MBR启动 |
mbr.binbootloader.bin |
mbr.bin |
MBR编译后的二进制文件 | mbr.asmboot.inc |
bootloader.bin |
BootLoader编译后的二进制文件 | bootloader.asmboot.inc |
mbr.asm |
MBR源文件 | - |
bootloader.asm |
BootLoader源文件 | - |
boot.inc |
头文件 | - |
根据新的依赖关系,可以编写新的makefile文件如下,其中除了添加了新的依赖文件编译规则外,还添加了对头文件路径的指定
1 | ASM_COMPILER := nasm |
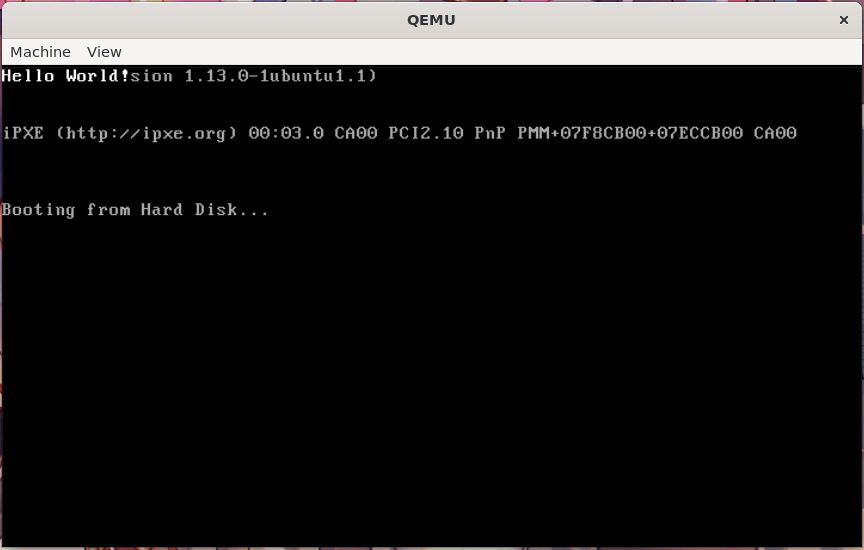
运行的方式与上一章相同,进入build/目录下执行make clean build run即可以对代码进行编译和运行
运行的结果应该与上一章一样,在屏幕的第一行打印出Hello World!字样
在BootLoader中开启保护模式
知识准备
保护模式
保护模式是目前英特尔处理器主流的运行模式,在保护模式中,处理器以32位模式运行,所有的寄存器也都为32位,因此程序可以访问到的内存空间
保护模式提出了 段 的概念,在CPU产生地址以后,会判断这个地址是否超出了段所规定的地址,从而避免程序之间的越界访问
除此之外,保护模式还包括了特权级保护等,在后面的实验中会逐个涉及
上面提到,在保护模式中提出了段的概念,在保护模式中运行的各种代码都需要声明自己所使用的段,并且由CPU监视地址的访问是否越界。那么,代码是如何告诉CPU自己所使用的段信息,CPU又是如何知道段的界限的呢?
实际上,为了能够让CPU得知段的具体信息,需要在内存中分配一段地址空间,在其中放置关于各个段的说明信息,这部分空间就被叫做全局描述符表GDT (Global Descriptor Table)
全局描述符表的起始地址与它的大小组合成一段48位长度的数据提供给CPU作为查询全局描述符表基地址的依据,放置在CPU中的GDTR寄存器中,GDTR的结构如下
| 位区间 | 描述 |
|---|---|
| [48:16] | 基地址 (Offset) [31:0] |
| [15:0] | 大小 (Size) [15:0] |
其中,大小由最多能够放入的描述符个数Count指定
全局描述符表看起来就像一个数组,其存放的都是64位长度的元素,每一个元素都用来描述一个段的信息,被称作段描述符 (Segment Descriptor),全局描述符表中的第一个元素始终为空描述符,从第二个元素开始可以由程序定义
对于段描述符而言,它由七个部分组成,结构如下
| 位区间 | 描述 |
|---|---|
| [63:56] | 起始地址 (Base) [31:24] |
| [55:52] | 标志位 (Flags) [3:0] |
| [51:48] | 段界限 (Limit) [19:16] |
| [47:40] | 访问控制位 (Access Byte) [7:0] |
| [39:32] | 起始地址 (Base) [23:16] |
| [31:16] | 起始地址 (Base) [15:0] |
| [15:0] | 段界限 (Limit) [15:0] |
其中,访问控制位又分为七个不同的部分,其结构和作用如下
| 位 | 缩写 | 描述 |
|---|---|---|
| 0 | A | 访问位 (Accessed bit)0:段未被访问1:段在上次清除这个访问位后被访问过 |
| 1 | RW | 读写权限位 (Readable/Writable bit) 代码段: 0不可读,1可读,始终不可写数据段: 0不可写,1可写,始终可读 |
| 2 | DC | 增长方向/一致性标志位 (Direction/Conforming bit) 代码段: 0只能由DPL中指定的特权级执行,1代表DPL中指定可执行的最高特权级数据段: 0段向高地址增长,1段向低地址增长 |
| 3 | E | 可执行位 (Executable bit)0:不可执行,为数据段1:可执行,为代码段 |
| 4 | S | 描述符类型位 (Descriptor type bit)0:系统段,例如TSS1:代码段或是数据段 |
| 5-6 | DPL | 描述符特权级 (Descriptor privilege level field)0:最高特权级(内核)3:最低特权级(用户) |
| 7 | P | 存在位 (Present bit)0:该描述符不可用 (invalid)1:描述符可用 |
段描述符的标志位则使用三个不同的标志设置了段的粒度、位模式
| 位 | 缩写 | 描述 |
|---|---|---|
| 0 | Reserved | 保留位,始终置0 |
| 1 | L | 长模式标志位 (Long-mode code flag)0:位模式由DB位指定1:段描述的位64位代码段 |
| 2 | DB | 位模式位 (Size flag)0:描述符对应16位保护模式段1:描述符对应32位保护模式段置位时 L位应为0 |
| 3 | G | 粒度标志位 (Granularity flag)0:描述符中的段界限按照字节单位计算1:描述符中的段界限按照4KiB单位计算 |
在了解了段描述符各个位的作用后,CPU又是如何通过这些地址和标志位去判断地址的合法性的呢?要明确这个问题,就需要首先知道CPU是如何生成地址的
进入保护模式之后,每当CPU生成一个地址,它实际上生成的是相对于段的偏移地址Offset,CPU同时还会通过上文中提到的段选择子从全局描述符表中取出段的基地址Base,之后CPU中的地址变换部件会判断偏移地址的合法性,并组合偏移地址和基地址得到真实的物理地址Address,这个最后的物理地址才会用于访问内存数据
也就是说,Address、Base和Offset之间存在如下关系
而CPU对地址合法性的检验,实际上就是在做Offset和段描述符中界限Limit之间关系的判断,当然,由于粒度Granularity的引入,在计算实际的界限时还需要掺入粒度单位
对于向上增长的段,它的偏移地址需要满足
这个很好理解,因为 代表着段中第一个字节的地址,而 代表段中最后一个字节的地址,偏移量需要介于这两者之间,才是合法的访问
陷阱:粒度不是直接进行乘4KiB的操作
实际上, 并不像我们想的那样将界限直接左移12位,而是相当于Limit << 12 | 0xFFF
也就是说,在4KiB粒度下,0xFFFFF的界限实际对应着0xFFFFFFFF,0x00000对应着0x00000FFF
对于向下增长的段,则稍微有些不一样,一个比较容易理解的阐述是,对于使用相同基址和界限的向上增长段,其合法地址在向下增长的段中不合法,其不合法的地址在向下增长的段中合法,如果使用公式来更严谨的解释这一说法,则偏移地址需要满足
举一个例子,假设需要在16位模式下设置一个1KiB栈段,其最高地址为0xFFFF,则其最低地址为0xFC00,大家可能很快就能想到,将基地址设置为0x0000并设置界限为0xFC00既可以描述这个栈段
但且慢,注意到偏移地址的最低合法地址为 ,如果界限设置为0xFC00,则最低合法地址为 ,栈的大小则不是1KiB,而是1KiB - 1了
因此,界限应该设置为0xFBFF才能让栈段的可用地址为1KiB
全局描述符表不仅可以存储段描述符
在之后的章节中,会了解到全局描述符表中不仅可以存放段描述符,还可以存放其他长度相同的描述符,例如任务状态段TSS (Task State Segment),这将会在实现用户进程的章节介绍
既然是数组,那就意味着可以通过下标(索引)来取出某个位置上的元素,CPU也正是这么做的,当一个程序向CPU声明自己所使用的段时,它实际上是向CPU提供了一个索引,这个16位索引中存储了其所使用的段在全局描述符表中的下标以及特权级信息(将会在用户进程的实现中介绍),被称作段选择子 (Segment Selector)
段选择子由其对应的段在全局描述符表中的索引、描述符表类型以及特权级构成,其结构如下
| 位区间 | 描述 |
|---|---|
| [15:3] | 索引 (Index) [12:0] |
| [2:2] | 描述符表类型 (TI)0:使用全局描述符表 (GDT)1:使用局部描述符表 (LDT) |
| [1:0] | 特权级 (RPL) [1:0] |
我们目前只需要设置索引位
由于在实验中不会使用到局部描述符表,因此在此处不会介绍它,这一位直接设置为0
同时特权级位会在后面涉及到用户进程时再次介绍,目前我们只需要关心RPL = 0的段
总的来说,操作系统内的代码首先在内存中的全局描述符表内声明需要用到的段,之后将对应段的选择子提供给CPU,CPU在产生地址后,根据选择子中的信息在全局描述符表中查询段的具体信息来判断访问是否越界
进入保护模式
在了解了保护模式以及全局描述符表的相关知识后,就可以编写代码在BootLoader中开启保护模式了
进入保护模式
进入保护模式有五个步骤,分别是 设置全局描述符表、关闭中断, 开启第21根地址线、打开保护模式开关 和 执行一次远跳转送入代码段选择子
首先进行第一步:设置全局描述符表
通过上一小节可以知道,全局描述符表实际上就是存放在内存中的一段类似于数组的空间,但是目前我们还没有指定这一段空间的位置,所以要先进行内存规划
实际上位置的指定相对自由,在实验中将GDT放置在0x9000-0x10000的位置处
| 用途 | 起始地址 | 终止地址 | 扇区数 |
|---|---|---|---|
| MBR | 0x7C00 | 0x7E00 | 1 |
| BootLoader | 0x7E00 | 0x8600 | 4 |
| GDT | 0x9000 | 0x10000 | - |
将新的常数写入头文件中方便调用
1 | ; BootLoader |
之后,在BootLoader中向GDT中添加元素,在实验中我们使用平坦模式,所以只需要添加代码段、数据段以及栈段的描述符,以及最初的空描述符
平坦模式
平坦模式就是所有的段都对所有地址空间有完整的访问权限,并且所有的程序使用同一个代码段,简化了地址的访问
之所以使用这个模式是因为在后面的实验中,会有另一套地址管理的机制,称为分页机制,地址的保护将会使用分页机制进行
可以根据段特性来设置描述符的值
| 段 | 起始地址 | 段界限 | A | RW | DC | E | S | DPL | P | L | DB | G | 描述符值 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 空 | 0x0 | 0x0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0x00000000_00000000 |
| 代码 | 0x0 | 0xFFFFFFFF | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0x00CF9A00_0000FFFF |
| 数据 | 0x0 | 0xFFFFFFFF | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0x00CF9200_0000FFFF |
| 栈 | 0x0 | 0x0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0x00CF9600_0000FFFF |
确定了描述符值以后,使用mov命令放置在给GDT分配的内存空间中
1 | ; Initialize Global Descriptor Table |
陷阱:注意小端模式
在IA-32处理器中,数据的存储使用的是小端模式
这就意味着对于一个64位的数据,低地址存放低32位,高地址存放高32位
虽然对于低32位,其存放顺序同样是小端模式,但是具体怎么放是mov指令的事情,我们就不需要关心了,我们只需要知道在使用mov指令的时候,宏观上要把低32位放在低地址上就对了
根据写入的顺序就可以设置描述符对应的选择子了,由于我们只使用GDT而且只考虑特权级为0的情况,因此选择子的低3位均为0
将选择子以及描述符个数写入头文件中方便重用
1 | ZERO_SELECTOR equ 0x00 |
设置好了GDT里的内容后,就要考虑如何将其装载入GDTR了
由于GDTR为糟糕的48位长度,很显然没有一个寄存器能够放下这样长度的数据,因此工程师们又想出了一个天秀的方式:先把要放入GDTR的值放置在内存的一段地址中,然后使用lgdt命令读取这个地址,由该指令将地址之后的48位数据拷贝到GDTR中
所以首先指定一段用于存放GDTR数据的内存
1 | ; Variables |
陷阱:注意小端模式
在汇编的变量声明中,先声明的数据位于低地址
由于IA-32处理器又是小端模式,所以GDTR中的Size段位于低地址,应该先声明,然后再声明其Base段
在BootLoader中由 这一公式来设置GDT的大小
1 | ; Set table size |
一切准备妥当后,就是用lgdt指令将这糟糕的48位长度数据送入寄存器
1 | ; Load gdt |
然后进行关中断操作
之所以要关中断,是因为在保护模式下中断的实现与实模式下不一样,在我们尚未实现中断的时候,贸然进入保护模式会产生错误。因此我们先在BootLoader中关闭中断,当我们在后续章节中建立起完善的中断机制之后再打开中断
1 | cli ; Disable interrupt |
在关闭中断后,就可以进行第三步:开启第21根地址线
在实模式下,CPU始终将21根地址线置为低电平,这样不论指令寄存器如何自增,始终会因为溢出而在0xFFFFF处回到0x00000
为了进入保护模式,就需要解除这一层封印,让寻址突破20位限制
在编写BootLoader中的代码前,可以先看一段有趣的代码来感受CPU是如何通过第21根地址线将地址限制在20位的
1 | ; The following code is public domain licensed |
至于打开这根地址线,由于该地址线由南桥A20端口控制,端口号为0x92,控制位位于第二位,因此代码编写如下
1 | ; Open A20 |
接下来就来到了保护模式真正的开关,CR0寄存器中的PE位
1 | ; Set PE |
最后执行一次远跳转,送入代码段选择子,正式开启保护模式,其中protected_mode_begin部分将在下一小节中完成
1 | jmp dword KERNEL_CODE_SELECTOR:protected_mode_begin |
远跳转
远跳转由两个部分组成:段选择子和段内偏移,执行远跳转会将段选择子送入代码段寄存器CS,同时将段内偏移送入EIP,使得CPU在新的代码段的基地址上以新的段内偏移开始执行指令
由于代码段选择子 不能够手动设置,因此只能够通过远跳转进行设置,所以此处执行的远跳转主要目的是为了送入代码段选择子
第二个Hello World
进入保护模式以后,自然要输出些什么才能确认前面的代码都正确无误地执行了。因此,在这一小节中就来实现保护模式中的第二个Hello World!
由于进入保护模式以后,代码全面进入了32位模式,所以也要添加对应的伪代码
1 | ; Protected mode starts here |
这时,我们还没有设置好各个段选择子,因此应当尽快将数据段和栈段的选择子送入寄存器,由于暂时用不到附加的段寄存器,所以不妨将它们设置为空描述符
1 | ; Set selectors |
接着就可以移植原先实模式下的代码,鉴于实模式与保护模式地区别,在移植时需要进行如下修改
- 寄存器由16位更换到32位
- 已然可以访问32位地址,不再需要
[gs:bx]这样的访问模式
陷阱:不是在32位模式下所有的寄存器都要使用32位
寄存器位宽的使用始终要符合数据的宽度,例如从内存取出字节的时候就应该使用寄存器的8位模式作为操作数,而不能一味地使用32位寄存器
移植后的代码如下
1 | ; Print something |
完整的bootloader.asm如下
1 | "boot.inc" |
完成
至此,就完成了本章的全部任务,赶紧使用make clean build run来测试代码的运行情况吧!
