操统实验日志 第四章 勇者之路
关于本章
在本章节的第一部分中,将会简要介绍在下一章中将要编写的KernelLoader,以及在开始着手进行它的编写之前所需要完成的,包括各种驱动、文件系统接口等在内的诸多准备工作。
在第一部分之后,我决定按照KernelLoader中的函数调用顺序,逐节完成KernelLoader中所需要的所有准备工作,因此在第二部分中,将会首先记录如何在项目中使用C语言和汇编混合编程,包括C语言是如何进行函数调用的,以及内联汇编中NASM向AT&T迁移语法所需要注意的问题。有了这部分基础知识,就可以进行第三部分编写一些常用的驱动,并从我个人的角度讲讲为什么要这么做,它对后续的代码编写能够起到哪些帮助。
在之后的第四部分中,会进行有关文件系统的知识的详述,并且带领大家阅读微软关于FAT文件系统的文档,根据文档完成FAT文件系统接口的设计和实现。
而第五部分则会关注如何在多个分区的磁盘上通过MBR读取不同分区的信息,从而为正确读取文件系统中的文件提供条件
在第六部分中,会介绍我个人认为的操作系统中最重要的概念之一的分页机制,并根据我对它的理解,完成对分页机制中主要数据结构的抽象。
如果你恰好像我一样,在第二部分中阅读的是人生中第一篇官方的文档的话,应当能够克服曾经对于文档的恐惧,甚至会在阅读后面的小节时仍意犹未尽,激动不已,那么第七部分将会趁热打铁,跟随关于ELF文件的文档完成对ELF文件格式中用到的主要数据结构的抽象。
本章内容提示:
是的,这一章内容确乎是超乎我想象得多,这也就导致了学校官方教程中绕过了这一部分直接进入Kernel先着手编写Kernel中的内容
事实上,就实现 从BootLoader加载到Kernel 这一步骤,甚至KernelLoader都并不是必须的,但省略这一部分并不是没有代价的:由于省去了进入Kernel前的分页机制准备工作,学校教程不得不在第八次实验中返回BootLoader,添加开启分页的代码
除此之外,在我们要实现的ElfLoader的加持下,Kernel不再需要以.bin的形式编译,也不再需要单独的entry.asm文件作为入口,并且可以加载到任意指定的地址处
最后一个跳板:KernelLoader
在上一章中,已经成功地从MBR跳转进入了BootLoader并且在BootLoader中开启了保护模式。
在成功开启了保护模式之后,其实就已经可以进入内核运行了。事实上,学校的教程也确乎是这么实现的:就如同MBR跳转BootLoader那样,将内核编译为.bin文件并从BootLoader加载后跳转到内核加载地址上运行。
而我的实现则相较于学校教程而言复杂了许多,在我的实现中,BootLoader与Kernel间额外添加了一层跳板,也就是在下一章中要完成的KernelLoader,它负责从硬盘活动分区的/system/文件夹中读取kernel.elf文件,并且解析kernel.elf文件中的信息,将内核加载到正确的地址,之后开启分页机制,最后跳转到Kernel运行。
看上去,学校教程的实现方式更加简单,但这样的捷径并非没有代价,至于学校教程有哪些弊端,以及为什么我采用了一条这样的路线,在后续小节和章节的实现中,都会渐渐明朗。
为了完成这样一个复杂的跳板程序,需要为其做许多的前期准备工作:
- 驱动准备:文件读取离不开对硬盘的读写操作,硬盘的读写则离不开对接口的读写。自然,使用类似于MBR和BootLoader中使用汇编是一种解决方式,但是为了增强代码可读性,不妨使用C++对这部分操作进行包装,提供接口供程序使用
- 文件系统的抽象:为了能够让程序能够识别硬盘中的文件系统,并且从文件系统中找到需要的路径和文件,就需要对文件系统的组织结构进行抽象,提供更为直观的函数接口供程序调用
- MBR的抽象:对于一个多分区的磁盘,MBR会存储关于分区的位置信息和属性,如果需要加载磁盘分区文件系统中的文件,那么从MBR获得关于分区的信息就是必不可少的第一步。因此需要了解数据在MBR中是怎样存储的,以及怎样从MBR中提取关于分区的信息
- 页表结构抽象:在后面实现虚拟地址和分页机制时,需要用到一些特殊的数据结构,将这些数据结构抽象成类并提供接口可以大大提高代码的可读性
- Elf文件结构抽象:
.elf文件中包含了一个加载并执行一个程序的诸多关键信息,例如程序需要加载到的地址、程序的入口点等等。为了解析文件内的信息,需要像文件系统一样,对.elf文件的结构进行抽象,最后提供接口供程序使用
这也就意味着我们的项目目录也会产生一些变化:
- 由于需要实现一系列驱动,所以需要在
src目录下添加driver文件夹 - 需要实现端口和硬盘的驱动,所以需要在
driver文件夹下添加hdd和port文件夹 - 由于需要实现许多抽象后的结构,所以需要一个
struct文件夹 - 需要对文件系统、ELF文件、MBR和页表进行抽象,所以需要为它们的文件准备
fs、elf、mbr和paging文件夹 - 同时,操作系统的代码还会依赖一些可重用的功能函数,例如常用的字符串处理函数、
memcpy、memset等等,这些都可以被称作操作系统需要用到的“库”,可以放在src目录下的lib文件夹中。同样,抽象后的结构也可以看作库的一部分,所以将struct文件夹也放置在lib文件夹下。 - 在之后的代码中还会用到一些通用的常数值和一些常用的类别如
unsigned int、unsigned char和unsigned long long和它们的别名uint32、uint8和uint64等等,可以将它们编写到头文件constants.h和types.h中。由于它们同样可以视为操作系统库的一部分,所以可以放在lib中叫做common的文件夹下 - 此外,可以提前为内核准备文件夹
kernel,放置在src目录下
在准备妥当后,新的项目结构如下
1 | . |
现在,就让我们开始接下来激动人心的旅程吧!
熟悉的朋友:C++闪亮登场
大家不会觉得KernelLoader要使用汇编完成吧,不会吧不会吧
离开了实模式进入32位保护模式后,C++就已经可以大展身手了,也就是说,从接下来开始就将脱离汇编苦海,投入C++的怀抱之中了。
不过,在正式开始C++的工作前,需要完成一些交接的工作,在这一小节中,将会介绍一个C++程序是如何从源文件编程可执行文件的,以及如何进行C++与汇编的混合编程
从代码到可执行文件
参考:
本节内容参考了学校教程第四次实验中从代码到可执行文件一章以及C/C++和汇编混合编程一章的内容
在编译器将代码编译成可执行文件的过程中,其实际上进行了四个步骤:预处理、编译、汇编和链接
预处理又称为预编译,在这一环节中,编译器主要处理宏定义,如#include, #define, #ifndef等,并删除注释行,还会添加行号和文件名标识,在编译时编译器会使用上述信息产生调试、警告和编译错误时需要用到的行号信息。
经过预编译生成的.i文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到.i文件中
我们可以通过新建一个简单的C程序main.cpp来测试这一步骤:
1 |
|
之后在编译命令中使用-E参数只进行预编译步骤
1 | gcc -o main.i -E main.cpp |
查看Linux关于指令的手册:
如果想要知道关于某一程序参数的具体描述,可以使用man命令
例如,man gcc可以查看关于gcc所有参数的描述和用法,其中关于-E参数就有如下描述:
-E Stop after the preprocessing stage; do not run the compiler proper. The output is in the form of preprocessed source code, which is sent to the standard output.
可以看到生成了一个main.i文件,其内容如下:
1 | # 1 "main.cpp" |
编译是将预处理后的代码翻译成汇编语法的步骤,具体包括了词法分析、语法分析、语义分析及相关的优化、中间代码生成以及目标代码生成五个环节
在gcc中使用-S参数可以进行编译步骤,-masm=intel指定输出的语法格式为第二章中介绍的Intel汇编语法
1 | gcc -o main.s -S main.cpp -masm=intel |
生成的main.s文件如下:
1 | "main.cpp" |
在汇编步骤中,编译生成的汇编代码将会被翻译成机器语言,并且组织成为可重定位文件的格式。在Linux下,可重定位文件是ELF格式,关于ELF格式的文档中详细地介绍了ELF格式中的各个部分,以及它们如何对重定位起作用。
ELF文件有多种类别:
ELF不仅可以用来描述需要重定位的文件,也可以用在链接环节的生成的可执行文件中,在本文的第六部分中,就要根据文档来介绍如何解析一个可执行的ELF格式文件
汇编步骤仅仅只是将单个的文件转换成了机器语言,如果项目中有许多文件,它们中又存在着调用关系的话,此时是没有办法执行的。可以这么理解:在编译器进行汇编的时候,它会遇到一些只有声明而没有定义的符号,例如一些外部函数和变量,这部分函数和变量的地址此时还并不知道,因此编译就会将它们标记起来,放置在ELF文件一些特殊的区域存储
在链接步骤中,链接器接受多个输入的可重定位文件,根据输入的参数设置,可以规定程序的入口点地址、程序代码段放置的地址等,然后按照设置的地址将文件中的各个部分组合拼接在一起。
由于在链接的步骤中,程序起始的地址通过参数规定,同时所有的文件此时都“齐聚一堂”,每个文件各个代码段就可以像安排座位那样依次入座了,整个程序各个符号的绝对地址也就确定了。这样,原先那些没有定义的符号此刻也能够找到了,并且也具有了绝对的地址值,各个文件中的相对地址此刻也都有了对应的绝对地址值,链接器根据这些新确定的绝对地址替换掉类似jmp、call中原先使用的值,将整个程序完整地串联在一起。
类似jmp这样的跳转指令,就是在链接的步骤中,才真正确定跳转的绝对地址的。
C++与汇编混编
即便有了C++这一利器,在实验中的许多地方仍然不可避免会需要用到汇编语言,例如需要操作某个特殊寄存器或是需要读写端口的时候。在这种情况下,有两种可行的解决方案,分别是 内联汇编 和 调用汇编函数
学校所提供的教程在第四次实验的C/C++和汇编混合编程这一部分介绍了调用汇编函数这一解决方案
在这个解决方案中,主要需要三个步骤:
- 将需要通过汇编实现的功能通过汇编函数的形式写在
.asm文件中,并声明global - 在需要调用函数的C程序头文件中提供
extern "C" boo baz()这样的外部函数声明,并在程序中调用这个函数来执行对应的功能 - 在链接步骤中将汇编和C程序一同链接
此外,为了能够让汇编函数的编写和调用能够顺利进行,还需要了解编译器是如何处理带参函数的调用的,我们不妨写一个带有参数的函数来试一试
1 | void func(int a, char b) { |
之后使用编译器编译成汇编代码,其中main函数对应调用func部分的代码如下
1 | push 65 |
可以看出,两个push操作分别向栈内压入了'A'和1两个参数,之后使用call指令调用函数,在函数返回后再使用add esp, 8将参数移出栈,
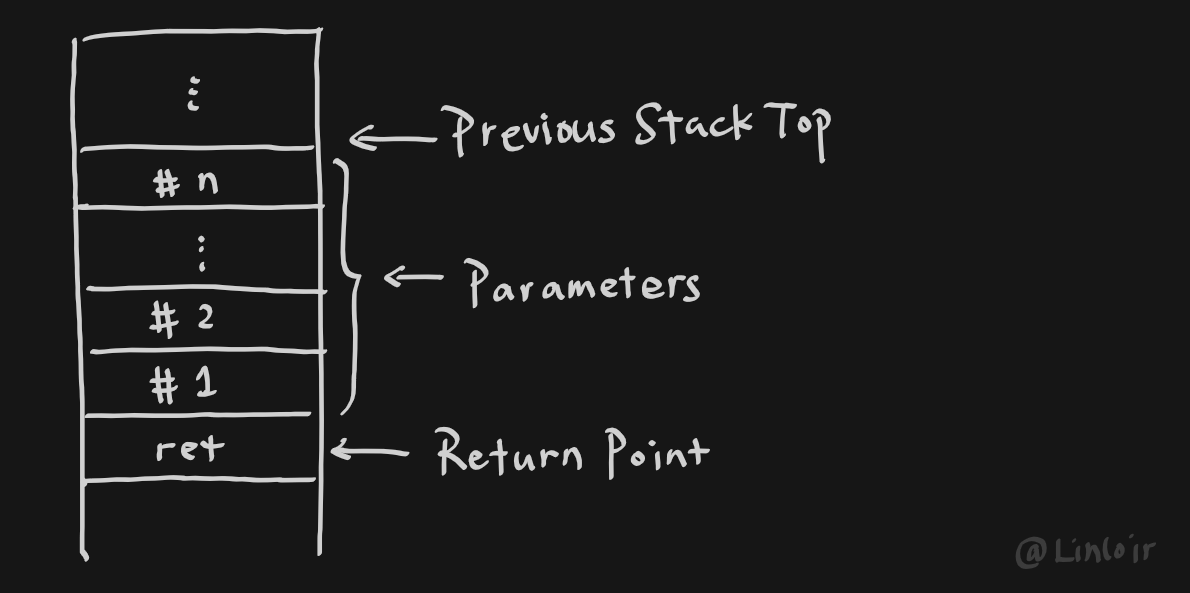
进入函数内也不能干坐着,按照C语言的规定,被调函数需要使用ebp从栈上取值,同时还需要为主调函数保留ebp寄存器的值,因此可以看到在汇编被调函数内部有这样的代码
1 | push ebp //Preserve ebp |
当然,尽管C语言似乎并没有要求被调函数主动保存其他寄存器的值,但我个人而言还是习惯在进入函数之后进行一次pushad操作主动保存,这也就让固定的函数骨架变为了
1 | push ebp |
关于调用汇编函数的实例:
如果想要查看关于上述方案的实例,可以参考学校教程的第四次实验 Example 1 混合编程 相关内容
上述方法为了调用一个汇编函数还要额外添加一个.asm文件,实在是不够优雅,所以我在后续的实现中改为了使用内联汇编来完成汇编代码的部分
实际上,内联汇编的使用极其简单(对于实验中所需要用到的部分而言),由于主要需要和内联汇编打交道的地方几乎无外乎都是要么从寄存器读出一个值,要么往寄存器写入一个值,所以并不需要学习多么复杂的语法,够用即可
在GCC中使用内联汇编,只需要使用asm关键字,如果不希望编译器改动汇编代码顺序,可以额外添加volatile关键字,于是,一个最简单的内联汇编语句可以长这样:
1 | asm volatile( |
如果代码有很多行的话,就长这样:
1 | asm volatile( |
是否已经跃跃欲试了?且慢,内联汇编默认使用的是AT&T的语法,因此我们需要进行一次Intel语法向AT&T语法的迁移,在了解了Intel与AT&T语法的主要区别之后,我们不论是写.asm文件还是写内联汇编都将得心应手
参考资料:
关于语法迁移的内容,参考了 GCC 内联汇编与 Intel 语法迁移 一文
Intel和AT&T的语法区别,无外乎以下几点:
- 操作数位置相反:
在Intel语法中,一个带有目的操作数和源操作数的汇编指令为op [dest], [src]
而在AT&T语法中,这样的指令则为op [src], [dest]
也就是说,AT&T中源操作数和目的操作数在指令中的位置与Intel语法中相反 - 操作数写法:
在Intel语法中,寄存器直接写作寄存器名字,如eax;立即数直接写立即数值,如0x1000
而在AT&T语法中,寄存器前要用%标明,如%eax;立即数前用$标明,如$0x1000 - 寻址格式:
在Intel语法中,使用基址变址寻址方式的汇编代码格式形如[ebx + esi * 2 - 0x10]
而在AT&T语法中,同样的汇编代码应写为-0x10(%ebx, %esi, 2)
也就是,在AT&T语法中,使用了基址base、索引index、元素大小size以及偏移量disp四个量进行寻址,格式为disp(base, index, size) - 操作数大小:
在Intel语法中,对于寄存器和立即数间的操作并不需要提供操作数的大小,而在使用[]寻址的过程中,需要指定大小,如mov eax, word [ebx]
而在AT&T语法中,始终需要提供操作数的大小,其中b为byte,w为word,l为dword,q为qword(64-bit),操作数的大小附加在指令名称后,如movl、addl
最后,为了能够让内联汇编功能更强大,GCC还提供了一系列扩展的指令操作:
1 | asm volatile( |
可以看到,在正常指令的尾部,GCC允许程序员添加三个参数列表,类似于printf函数那样,通过在汇编代码中插入特定的操作数,并在后面的参数列表中按照规定的格式提供变量,可以使用变量来 “替换” 代码中对应的操作数,从而起到将变量值写入寄存器或是将寄存器值写入变量的操作。
其中,参数列表中每一个参数都由一个可选的名称[name],一个限制符如"=r"、"i"等以及对应的变量(var)组成。
限制符在实验中只需要用到"r"以及"i",其中
"r"代表可以使用任意的寄存器"i"代表立即整型操作数
除此之外,还有更多的限制符,如
"a"代表可以使用%eax、%ax、%al"b"代表可以使用%ebx、bax、%bl"c"代表可以使用%ecx、%cx、%cl"d"代表可以使用%edx、%dx、%dl"s"代表可以使用%esi、%si"D"代表可以使用%edi、%di"m"代表内存操作数"o"代表内存操作数,仅用于偏移量"V"代表内存操作数,仅用于非偏移量"n"代表立即整型操作数,允许已知的数值"g"代表允许任何寄存器,但寄存器不是常规的寄存器
在汇编指令中,可以用%0、%1…%n这样从零开始的数字来表示参数列表中的第一个、第二个、…第n个变量,例如
1 | int out_eax, in_eax = 10; |
也可以使用%[name]的方式通过名称来直接对应参数列表中指定名字的变量,例如:
1 | int out_eax, in_eax = 10; |
陷阱:额外的%
当使用了扩展内联汇编之后,由于诸如%0这样的操作数会使用一个%符号,为了区分,所有的语句中的寄存器都需要额外加一个%,例如movl %0, %%eax
陷阱:变量大小与指令操作数大小对应
例如,如果使用了movl指令,那么对应的参数列表中的变量也应当是32位长度,例如int
至此,内联汇编的优势已然显现出来,其不但减少了杂乱文件的数目,而且还可以方便的与C程序中的变量进行操作,在后续的实验中选择哪种方案相比心里也有了答案。
但不论选择哪一个方案完成C和汇编的混合编程,至此我们都已经顺利完成了进入C++语言环境的全部知识准备,足够我们进入后面的小节继续实验的进程了。
驱动:抽象硬件交互
在操作系统实现的各个环节中,都离不开和硬件打交道的部分,在我们已经完成的MBR中,就有我们为了加载BootLoader而写的读取磁盘扇区的函数。
这些需要和硬件进行通信的操作,往往都需要用到一些特殊的端口,通过我们实现MBR的经历可以知道,使用汇编的in和out指令就可以对端口进行读写操作,而这样简单的操作如果是使用C++这样的语言进行编程的话却是无法实现的。
这时,大家可能就会说了,不是刚刚学完了C++和汇编混编吗,这不直接上来就是一个asm ("inb dx, al"),很快啊!
不可否认,这不失为一个解决方式,但放在C++中,它就是显得不那么优雅:如果能把一个端口视为一个对象,比如port,直接port.read(),这才叫优雅嘛!
可喜的是,这在C++中是完全可以实现的:只需要实现一个类,其持有一个端口号作为成员变量,读写操作的实现则都使用内联汇编完成。
这样就相当于在汇编操作外附加了一层C++的外衣,将原先裸的内联汇编代码包装成了C++代码,不仅提升了代码的可读性,而且由于存在C++的类作为中间层,可以添加很多保护性的代码,比如判断非法端口的访问、只读端口的写入等等,相比直接操作裸汇编代码提升了安全性和灵活性。
端口驱动
在实现端口驱动的时候,可以根据端口的读写权限分为三个类:
Port类用来表示可读写的端口PortWriteOnly类用来表示只能写的端口PortReadOnly类用来表示只能读的端口
对于Port类,由于汇编中的in和out指令都需要提供端口号,而既然我们现在打算将一个端口封装成一个Port的实例,那就不能每次调用读写函数的时候都提供一次端口号,而是要让实例在初始化的时候就记住它应当是哪个端口。由于这个端口号只有在初始化的时候被赋值,之后就不再需要更改或是暴露给程序,因此可以作为私有的const变量进行储存:
1 | private: |
对于端口的读写函数,由于不同的端口位宽会存在不同,因此读写指令的返回值和参数的类型需要借助类模板的帮助:
1 | template<typename T> |
又因为在内联汇编中,in和out指令都需要指定操作数的宽度,如inb或是inl,因此在读写函数的实现上,要使用sizeof(T)对模板类的类型参数位宽进行判断,再使用合适的内联汇编函数,例如:
1 | template<typename T> |
对于一个8位端口,使用内联汇编的读取代码可以首先将端口号读取到dx,再使用inb指令读取端口数据到al,最后将数据从al写入到外部变量:
1 | asm volatile( |
内联汇编在编译的时候会检查外部变量的大小是不是和对应指令中指定的操作数宽度相匹配,例如movw指令不能提供一个uint16类型的变量,因此如果直接将T data作为参数传入,会发生报错。对于这个问题,可以在使用sizeof()判断后,显示地将data转换为对应的大小,或是先赋值到一个明确宽度的变量(例如:uint8 _data)中,再在C++中赋值给原先的变量:
1 | template<typename T> |
由于只写或是只读的端口在读、写函数的实现上与可读写端口中的读写函数没有任何区别,因此在我最初的实现中将Port类作为基类而PortWriteOnly和PortReadOnly私有继承Port,之后封装父类中对应的函数为类的公有接口,例如:在Port中的public: void _write(T data)函数在私有继承后,在PortWriteOnly中添加public: void write(T data) { _write(data); }来调用基类中的写接口,而不对读接口进行封装,来实现读写权限的限制。
但在后续的实验中我发现,即便父类中的函数由于继承已经实质是类的私有函数,但在Intellisense中仍然可以看到,感觉还是不够安全。因此我决定不继承的方式,转而对于PortWriteOnly存储一个Port类型的成员变量代替Port中的端口号,在写函数中调用Port::write函数,彻底杜绝在PortWriteOnly中出现read函数的提示。
1 | template<typename T> |
完整的端口驱动ports.h如下:
1 |
|
陷阱:模板类的函数应在头文件中定义
模板类的函数不能将函数声明写在头文件中,而将函数的定义写在另一个文件中,这样会导致在编译链接的时候出现无法找到函数定义的报错。所有的模板类函数都需要在头文件中就实现函数的定义。
硬盘驱动
回顾:从硬盘读取多个扇区的数据
关于如何使用LBA模式通过端口读写磁盘,可以回顾第三章中相关内容的介绍
要将硬盘的读写操作抽象成驱动,在实验中使用了与第三章中相同的PIO模式对硬盘进行访问,在这个模式下与硬盘通信需要使用到8个不同的端口:
| 端口号 | 端口数据传输方向 | 作用 (LBA28) | 描述 | 位长 (LBA28) |
|---|---|---|---|---|
| 0x1F0 | 读/写 | 数据寄存器 | 硬盘读出/要写入的数据 | 16-bit |
| 0x1F1 | 读 | 错误码寄存器 | 存储执行的ATA指令所产生的错误码 | 8-bit |
| 0x1F1 | 写 | 功能寄存器 | 用来指定特定指令的接口功能 | 8-bit |
| 0x1F2 | 读/写 | 扇区数寄存器 | 存放需要读写的扇区数量 | 8-bit |
| 0x1F3 | 读/写 | 起始扇区寄存器 | 存放起始扇区0-7位 | 8-bit |
| 0x1F4 | 读/写 | 起始扇区寄存器 | 存放起始扇区8-15位 | 8-bit |
| 0x1F5 | 读/写 | 起始扇区寄存器 | 存放起始扇区16-23位 | 8-bit |
| 0x1F6 | 读/写 | 磁盘、起始扇区寄存器 | 选择磁盘和访问模式 存放起始扇区24-27位 |
8-bit |
| 0x1F7 | 读 | 状态寄存器 | 读取当前磁盘状态 | 8-bit |
| 0x1F7 | 写 | 指令寄存器 | 传送ATA指令 | 8-bit |
既然前面已经实现了端口的驱动,那么在这里就可以直接投入使用了,将列表中的端口按照对应的读写权限和用途实例化作硬盘类HDDManager的私有成员变量:
1 | private: |
注意到,对于0x1F7端口,当其作为读端口时用来表示硬盘的状态,其表示形式为按位枚举,端口读出值的每一位都有对应的含义:
| 端口号 | 位 | 缩写 | 作用 |
|---|---|---|---|
| 0x1F7 (Read) | 0 | ERR | 指示是否有错误发生,通过发送新指令可以清除该位 |
| 0x1F7 (Read) | 1* | IDX | 索引,始终置为0 |
| 0x1F7 (Read) | 2* | CORR | 修正数据,始终置位0 |
| 0x1F7 (Read) | 3 | DRQ | 0:硬盘还不能交换数据1:硬盘存在可以读取的数据或是可以写入数据 |
| 0x1F7 (Read) | 4* | SRV | 重叠模式服务请求 |
| 0x1F7 (Read) | 5* | DF | 驱动器故障错误 |
| 0x1F7 (Read) | 6* | RDY | 0:驱动器发生了减速或是错误1:驱动器运转正常 |
| 0x1F7 (Read) | 7 | BSY | 忙位0:空闲1:忙 |
什么是按位枚举:
按位枚举就是指利用二进制位来表示某个事物的属性,不同的二进制位描述不同的属性。
例如,对于一个人的特征来说,可以用所在的位表示性别,1为男,0为女;用所在的位表示是否是短发,1为是,0为否,等等。
需要注意的是,在使用按位枚举的时候,不同的二进制位应当描述不同的属性,例如如果要表示性别应当使用一个二进制位的0和1来区别,而不是使用两个二进制位,一个置位表示男,另一个置位则表示女。
由上述的列表中可以看出0x1F7中的每个二进制位都确实描述了一个硬盘状态的不同属性,对于这样的二进制位枚举,可以通过enum来表示:
1 | enum HDDStatus { |
但糟就糟在C++对按位枚举的支持并不好,由于C++默认将枚举类型作为整型值处理,所以常见的按位操作是默认支持的:
|:按位或,合并存在的属性&:按位与,用掩码取出某个属性的值,例如flag & 0x0F可以单独取出低四位的属性值~:按位取反,用来反转所有属性值^:按位异或,用来反转某个属性值,例如flag ^= 0x08可以反转第4位属性的值
但如果想重载一些特殊的运算,或是添加一些特殊的判断函数,枚举类型则显得无从下手了:
-:删除某个属性+:添加某个属性contains(flag):判断是否包含flag中的全部属性
为了支持这些操作,可以使用C++的类对原本的枚举类型进行一次封装:将枚举类型声明在C++类内,使用一个私有变量存储实际的枚举值,并通过重载运算符的方式从而让类的实例能够支持上述所有的运算操作。
对于目前而言,为硬盘的状态属性定义类HDDStatusFlag,并将原先的枚举类型声明在这个类内:
1 | class HDDStatusFlag { |
这样,如果想访问枚举类型中的某个常量值,例如BUSY,可以使用HDDStatusFlag::BUSY或是HDDStatusFlag::ATTR:BUSY访问到。
由于0x1F7端口为8位端口,所以对于HDDStatusFlag这个枚举类,其实际需要存储的数据为byte类型,因此可以使用一个byte类型的变量作为其私有成员,用来存储实际的枚举值:
1 | private: |
为了能直接使用整型值给HDDStatusFlag类型的变量赋值,需要定义一个参数为byte类型的构造函数:
1 | public: |
有了这样的一个构造函数,类的实例就可以使用如下的方式构造了:
1 | HDDStatusFlag flag = HDDStatusFlag::ERR_OCCURRED | HDDStatusFlag::BUSY; |
至于其他的按位操作、特殊运算和判断函数的实现此处就不再赘述,无外乎就是对运算符进行重载,然后再对实际的值进行对应的运算或判断即可。
在完成了硬盘硬盘状态类的设计后,就可以开始实现硬盘的读写函数了。以硬盘的读取为例,其分为两个主要的步骤:从硬盘读取以及写入内存中的缓冲区。
由于目前在KernelLoader中没有一个完善的内存管理机制,而进入内核之后内存将可以通过堆分配器分配空闲的内存供程序使用,两者在内存申请上会存在很大的区别。
如果让HDDManager自行管理其在读写时需要用到的缓冲区的话,就需要分别为KernelLoader环境和内核环境设计不同的缓冲区申请和释放的机制,相当麻烦。考虑到驱动的通用性,所以不妨让内存申请的步骤对HDDManager这个类完全不可见,由调用读写函数的调用者主动申请对应大小的内存,并将申请到的内存首地址作为参数传递给读写函数,所以读写函数的签名声明如下:
1 | public: |
在读写函数的实现上,可以将多个扇区的读写拆分为多个单独扇区的读写,将单个扇区的读写函数作为私有成员仅供公有读写函数调用。
1 | private: |
以读取的函数为例,单个扇区的读取步骤如下:
- 向
_secCntPort端口写入读取的扇区数量0x01 - 向
_lbaLoPort端口写入读取的扇区号低8位 - 向
_lbaMidPort端口写入读取的扇区号8至15位 - 向
_lbaHiPort端口写入读取的扇区号高16至23位 - 向
_drivePort端口写入读取的扇区号高4位以及驱动的参数0xE0 - 向
_cmdPort端口写入读取命令0x20 - 等待硬盘就绪,从
_statusPort中读取硬盘的状态,如果状态包含了HDDStatusFlag::DATA_READY属性,则意味着硬盘数据准备完毕 - 读取512字节到缓冲区中
其中,如果在等待硬盘就绪的步骤中发生了错误,则会使用false返回值表示读取失败。
具体的实现如下:
1 | bool HDDManager::_readOneSector(uint idx, byte* dst) { |
在读取多扇区的函数中,如果读取某个扇区时_readOneSector函数返回了false值,则会进而读取_errPort中的错误信息,写入缓冲区首2字节中,并返回false告知主调函数在硬盘读取过程中出现了错误。如果没有遇到错误,则继续下一个扇区的读取,然后向主调函数返回true。
具体的实现如下:
1 | bool HDDManager::readSector(uint idx, uint cnt, byte* dst) { |
对于硬盘写,操作则与硬盘读大同小异,仅仅是将数据的传输方向颠倒,从由_datPort读出数据变为向_datPort写入数据,从写入缓冲区变为从缓冲区取出数据而已,此处便不再赘述。
完整的hdd.h头文件如下:
1 |
|
头文件中的函数定义则都存放在hdd.cpp中,完整的内容如下:
1 |
|
现在,如果想要从硬盘中读取某个或是某几个扇区,例如,读取5~12扇区,则可以调用HDDManager中的readSectors函数如下:
1 | //Request buffer |
可以看到,代码明显比原先使用汇编时更加地简洁,也更易于阅读,这也就是编写驱动的目的。
抽象FAT文件系统
在BootLoader开启了保护模式之后,所有的一切操作,包括上一小节中编写的驱动都是在为了内核的加载而铺路。
加载:
这里及后文中说的加载,都包括了将内核编译后的输出文件读入内存中以及将内核的各个部分放置在正确的物理地址处这两个步骤
加载这一个环节又自然离不开将内核编译后的可执行代码从硬盘读入内存的步骤
在学校教程的实现中,内核被编译为裸二进制文件,也就是.bin文件,像MBR和BootLoader那样直接写入硬盘对应的扇区。在读取的时候,由于写入的起始扇区和扇区数量都已知,所以可以直接从硬盘读取对应的扇区到内存中。由于内核已经被编译为裸二进制文件,只需要将整个文件读取到对应的地址处就完成了内核的加载操作,而不需要额外的操作。
固然,使用这个方式是简单而且方便的,但我始终觉得这样不够优雅。于是我简单地了解了Linux中一个叫做grub的启动引导程序,简单来讲,grub的启动分为了三个阶段:
- 第一个阶段 (stage 1) 就基本相当于我们所编写的MBR部分,其负责从硬盘上加载中间阶段 (stage 1.5) 的代码的首扇区,也就相当于我们的BootLoader
- 这个中间阶段 (stage 1.5) 首扇区代码负责将剩余代码载入内存,之后剩余代码会找到活动分区下
/boot/grub/目录中的启动程序,也即第二阶段程序 (stage 2),然后加载到内存运行 - 在第二阶段 (stage 2) 中,程序会解析
/boot/grub/grub.cfg文件,显示一个启动菜单给用户,并且负责加载对应系统中的内核运行
GNU GRUB
关于grub的更多信息,可以查看Wikipedia上关于grub的页面
由于grub在中间阶段就引入了对文件系统的加载,从而可以从分区目录中读取需要的文件,看起来就比直接读取裸二进制文件要优雅得多了。因此我决定放弃学校教程的思路,转而在KernelLoader中实现一个简单版的grub程序,其可以从分区的/system/目录下找到内核文件并加载。
为了能够在KernelLoader中读取分区中的目录和文件信息,就必须要让代码能够解析分区上的文件系统,由于FAT是一个成熟且简单的文件系统,所以在实验中硬盘采用了FAT格式进行格式化。
尽管文件系统中存储的文件不尽相同,但对于同一个格式的文件系统,它们又都有着相同之处,例如文件系统包含了哪些结构,文件在文件系统中是怎样被组织的等等,这些不同中的相同之处就是我们解析文件系统的关键之处。
我们现在所需要做的就是用代码表示出这些相同的部分,并探究这些相同部分中的信息如何给文件的读取以提示,如何帮助我们了解文件系统中的内容。在下一章中,我们会更进一步,了解如何通过这部分信息从文件系统中读取需要的文件。
抽象:
通过代码去表现共同点,并用接口从共同点中提取出需要的信息,从而能够去解析那些特异的数据,这其实就是抽象的过程。
简述文件系统与FAT
参考资料
如果想要了解关于文件系统的更为权威、详细的信息,可以阅读课本《操作系统概念》中第四部分关于文件系统的内容,我强烈建议先完成这部分的阅读再继续后面的实验。
除此之外,Bilibili上南京大学操作系统课程中关于FAT和UNIX文件系统知识的讲解是不错的视频资料,其前半部分讲解了文件系统的原理以及FAT的一些基础知识。
文件系统是对文件的一种组织形式,所以文件固然也就是文件系统中至关重要的部分,了解文件系统首先就要了解文件的构成。
不论是哪种类型的文件,不论是.doc、.ppt还是.txt抑或是.bin,在硬盘的视角来看,它们中的数据实际上都是一系列二进制的数据块,而类别的区别只在于这些数据内部的组织形式,并不会让它们看起来是除了二进制数据块以外的其他样子。
但是如果一个文件只有数据块又不太够,文件名称是用户用以区分不同文件的关键信息,文件名称有时候对于文件系统来说太复杂了,所以文件系统会用一些特殊的方式记录用户提供的文件名称并通过其来识别不同的文件,这种记录有时候会呈现以标识符的形式,在FAT文件系统中则是一系列字符串。
除此之外,文件还需要一些其他的信息,例如其类型、数据在硬盘上的位置、尺寸、访问权限、创建或修改日期等等。
可见,文件由两个关键的部分组成,一个是文件的数据,也就是一系列二进制数据块,另一个则是文件的信息,它用来区分不同的文件并在硬盘上定位到文件数据的位置。
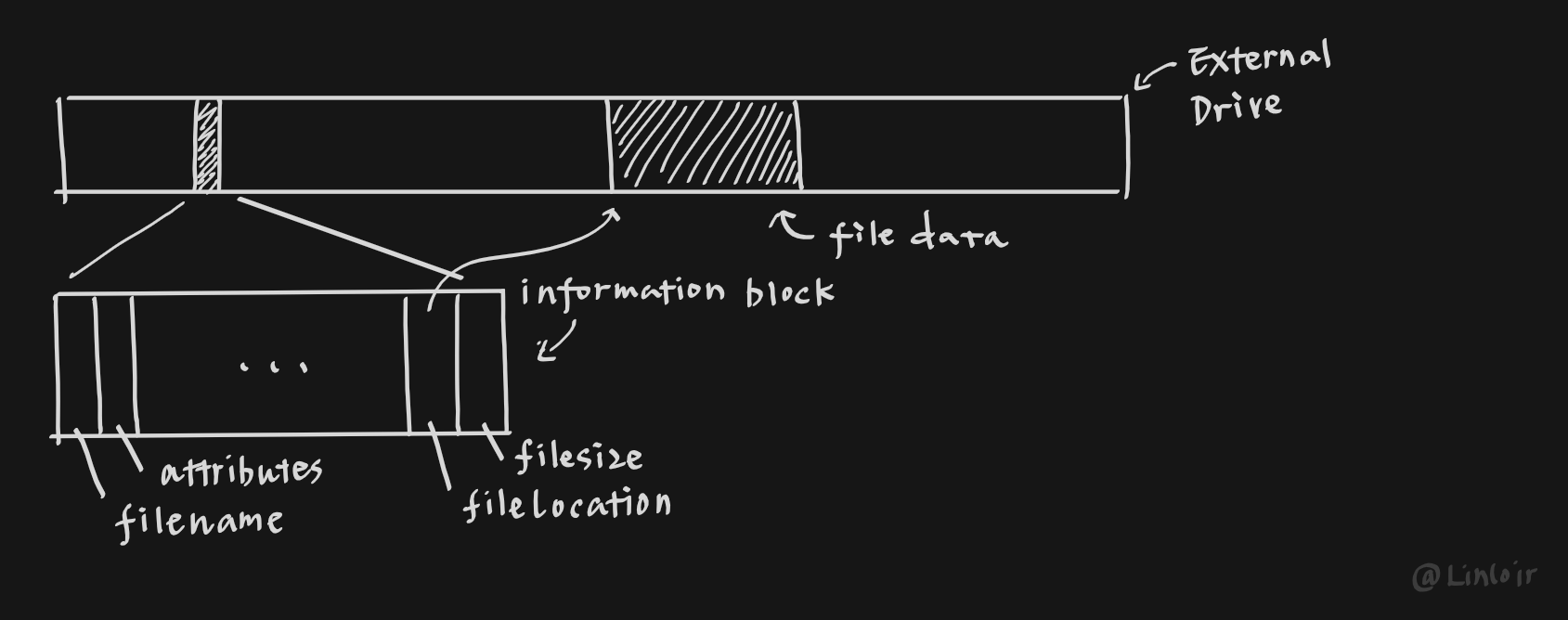
在文件系统组织文件的时候,其实际上就是在建立索引文件的数据结构,由于文件是由两部分构成的,文件系统中也就存在着两种主要的数据结构,分别用来索引文件的这两个组成部分。
其中一个数据结构用来索引文件的信息,这部分数据结构一般呈现树形的结构,文件系统中的文件目录就是由这个数据结构所维护的,树中每个节点都存储着一个文件或是目录的信息。
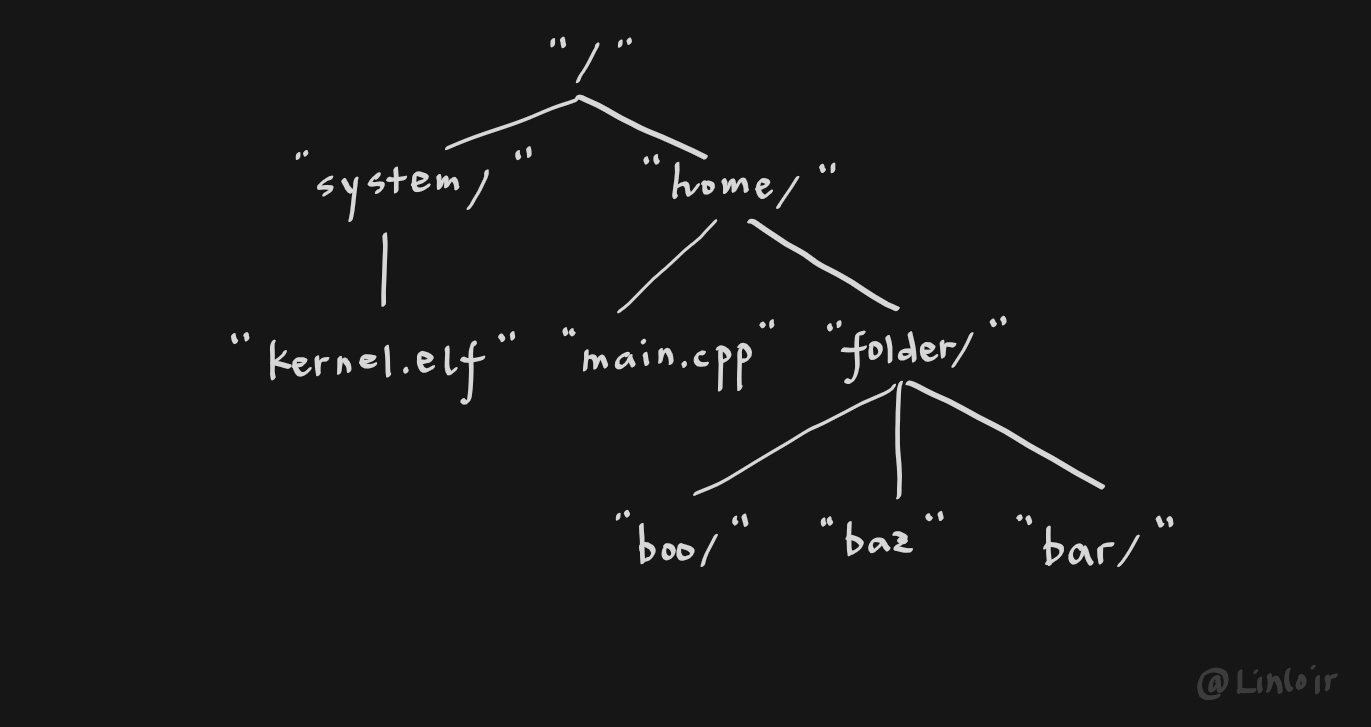
另一个数据结构则用于通过文件的信息来索引文件的数据,由于一个文件可能跨越数个甚至数十、数百个扇区,由于文件时时刻刻都可能会被更改,所以没有办法预先给文件分配一段固定的、连续的、大小适当的空间,因此文件的数据往往分散在磁盘的各个位置,这时就需要一个数据结构来将这些游离的数据块串接起来。说到这里,可能大家就已经能猜到,这部分数据结构一般以链表的形式出现。每一个文件块都对应着一个下一文件块的位置信息,而第一个文件块的位置信息则存储于文件的信息中。
下图表示了一个文件系统磁盘中可能的样子:
#0标号的内存空间对应着系统的根目录/节点,其内部有两个有效的文件信息,分别是system和home,均为目录类别。system首文件块指向#8,并且#8为其最后一个文件块,因此#8实际上就对应着/system/节点,其中存储了kernel.elf一个文件的信息。- 对于
home,首文件块指向#14,其下一个文件块为#16,并且是最后一个文件块,因此#14,#16共同构成/home/节点,在这个节点中存储了两个有效文件信息,分别是boo.baz和bar,分别是文件和目录。 kernel.elf首文件块为#4,#4下一个文件块为#6,#6为最后一个文件块,因此kernel.elf对应的文件数据为#4,#6上的数据。boo.baz首文件块为#10,后续文件块依次为#12、#5。因此#10,#12,#5共同构成boo.baz文件的数据bar首文件块指向#18,后续文件块为#11,因此#18,#11共同构成了目录树中的/home/bar/节点的子树信息
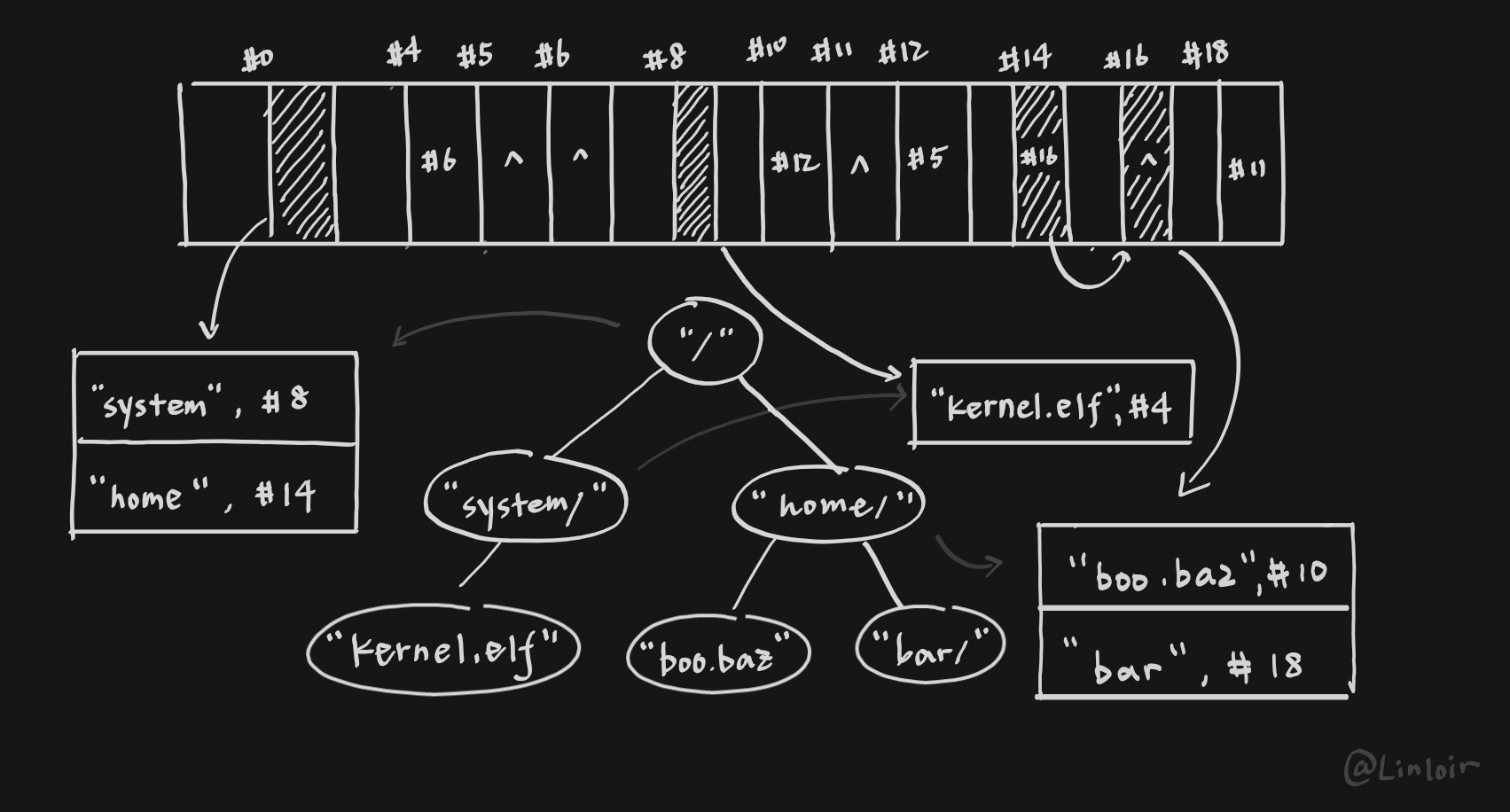
由上图可以看出,目录树的遍历方式是要与数据结构中树的遍历方式有很大不同的。每一个节点实际上都对应着一个存储着其子节点的文件的信息的数组,通过这个数组,可以获得子节点对应文件的首块信息,再依据链表就能够获得全部的文件数据。只有当取得了全部的文件数据,才可以进入下一层的节点。
简单来说,就是在/目录下,我们只能得到system/和home/的信息,但是我们不能从这些信息中直接得到system/下或是home/下有什么文件,除非我们把它们的数据完整地读取出来。
而在一般的数据结构中,对于根节点root,我们只需要访问child = root->children[0]就可以获得整个子节点,得到的child就包含了其所有的子节点数据,而不需要额外的加载操作。
现在,假设我们需要访问/system/kernel.elf文件,那么就需要
- 首先从树的根部开始,找到类型为目录,名称为
system的信息 - 从信息中读取出目录数据的第一个块
#8,并根据链表中的信息读入整个目录,由于这里只有一个块,所以就读入#8 - 在目录的数据中找到类型为文件,名称为
kernel.elf的信息 - 从信息中读出文件数据的第一个块
#4,并根据链表读入#6,得到整个文件。
不过,为了提高文件读写的速度,系统一般会维护一个打开的文件表 (Open-file table) 用于维护所有打开的文件的信息,所以一般来说,当打开一个文件的时候,除了会将它的全部数据就被读取到内存中,还会将其信息添加到打开文件表中,后续所有的增删改都只会对内存中的数据起作用,直到文件关闭时才再次写回磁盘。这样就避免了每次读写过程中对文件数据的定位以及读取。
好戏还在后面
关于操作系统如何维护打开文件表,以及更多更为复杂的操作,将会留到内核中实现
不过,上面只是对文件系统的一种简单的概述,不同的文件系统会有不同的组织文件的方式,但核心总还是离不开怎样组织文件的数据以及如何通过文件的信息索引到文件的数据,区别大抵是数据结构的差异以及具体实现上的差异。
例如,在上世纪出现的FAT中,由于软盘随机读取的性能奇差,所以如果像上文中图片绘制的那样,在文件数据块的末尾添加上下一个文件块的信息,糟糕的问题就会出现:如果尝试在文件尾部添加些什么,那需要遍历之前所有的文件块才能知道最后一个文件块在哪个位置!
为此,工程师们将所有文件块中关于下一个块的信息独立出来,存放在磁盘中的一个连续的空间内,这个空间也被称作文件分配表 (File Allocation Table),也就是FAT实际的意义。这样,只需要提前把这一部分空间读取到内存中,就可以很快地定位到文件任意个块的信息了。
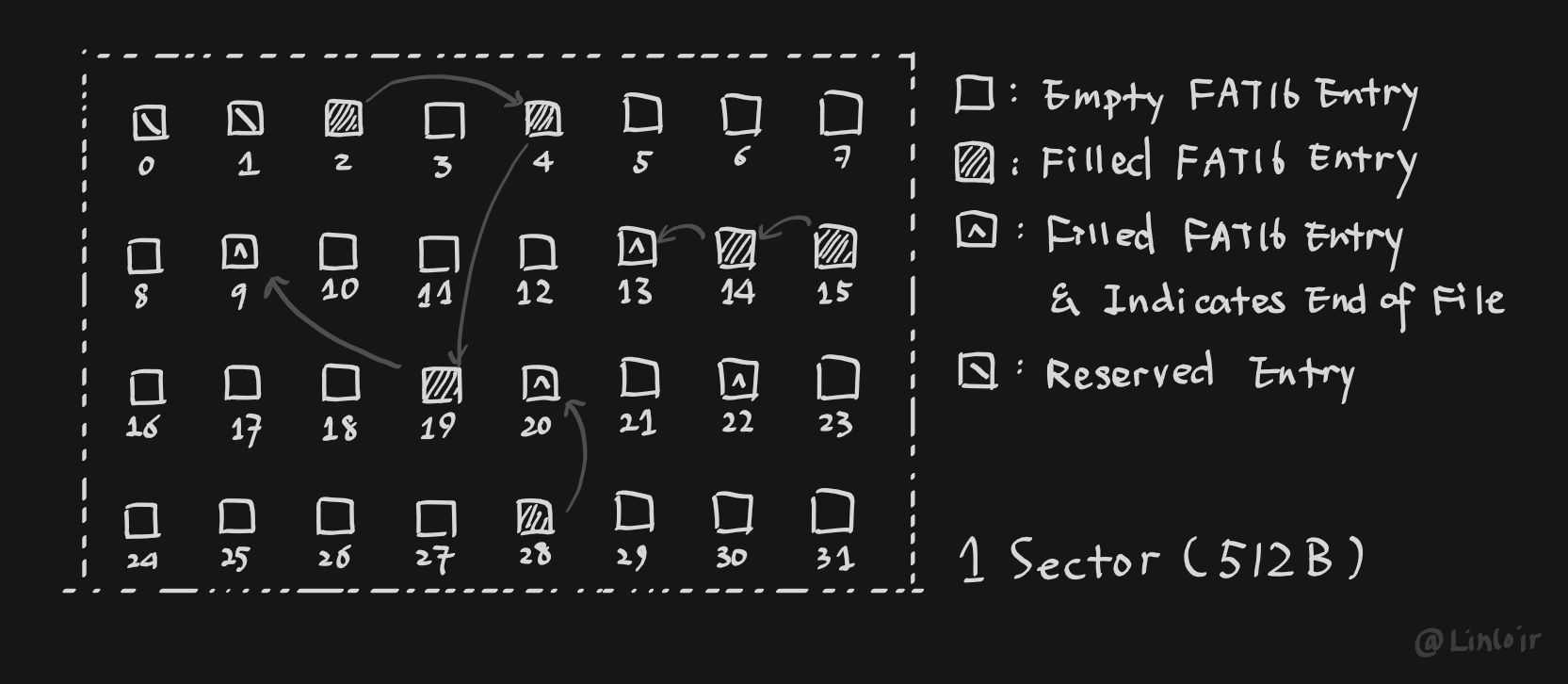
同时,这样做还有一个好处,一个512字节或是其整数倍的块需要分配几个字节给下一个块的块号,导致每个文件块实际数据大小不是2的幂,现在由于将这部分信息独立出来,所以每一个文件块都是完整的512字节或是512字节的倍数。
但是,如果每个数据块只占据1个扇区的话,对于大磁盘来说,需要的块号还是太多了,于是工程师就提出了簇 (cluster) 的概念,一簇由许多个扇区组成,而这个簇就相当于前文中的数据块。
这样,在FAT中存储簇号就大大减少了FAT的大小,虽然增加了碎片,但是提升了文件读写的效率。
碎片:
当一个簇很大的时候,例如4KiB,如果一个文件的大小为4KiB + 1B,则仍然需要为其分配8KiB的空间,也就是两簇。这就使得第二簇中几乎所有的空间都被浪费了,这部分空间就被成为碎片
第一篇文档
在了解了文件系统是怎样组织和存储文件之后,对于如何从文件系统中读取文件应该有了思路。
但是细细一想又会发现很多问题,例如:根目录存储在磁盘的哪个位置、如何知道一个簇有多大、文件名是如何存储的、怎样才代表当前的簇是文件的最后一个簇等等
这便是因为文件系统很多具体的细节还没有落实,程序还无法从现有的文件系统中获得需要的数据。而这就是本节的目的,通过阅读微软关于FAT文件系统的规范文档,对FAT文件系统进行抽象,并且提供接口来解决上面提到的种种问题。
定义与注解
第一章大体可以略过,其中较为重要的概念如下:
- 簇 (cluster): 文件分配的单元 (A unit of allocation),其中包括了一组逻辑连续的扇区。卷内的每个簇都可以通过一个簇号N指代 (referred to)。给任何一个文件所分配的全部空间的大小 *(All allocation for a file)*必须是簇的整数倍。
- 分区 (partition): 在一个卷内的一系列扇区
- 卷 (volume): 一个逻辑上的连续的扇区地址空间
卷结构
第二章主要介绍了FAT格式卷的结构,除了上文中提到的用来存储下一个簇信息的FAT区域 (FAT Region) 以及存储文件数据的区域 (File and Directory Data Region) ,还包括了一个保留区 (Reserved Region) 和一个根目录区 (Root Directory Region) 。
根目录区在FAT32格式的卷上不存在
一个FAT格式的卷结构大概长得就像下面这样
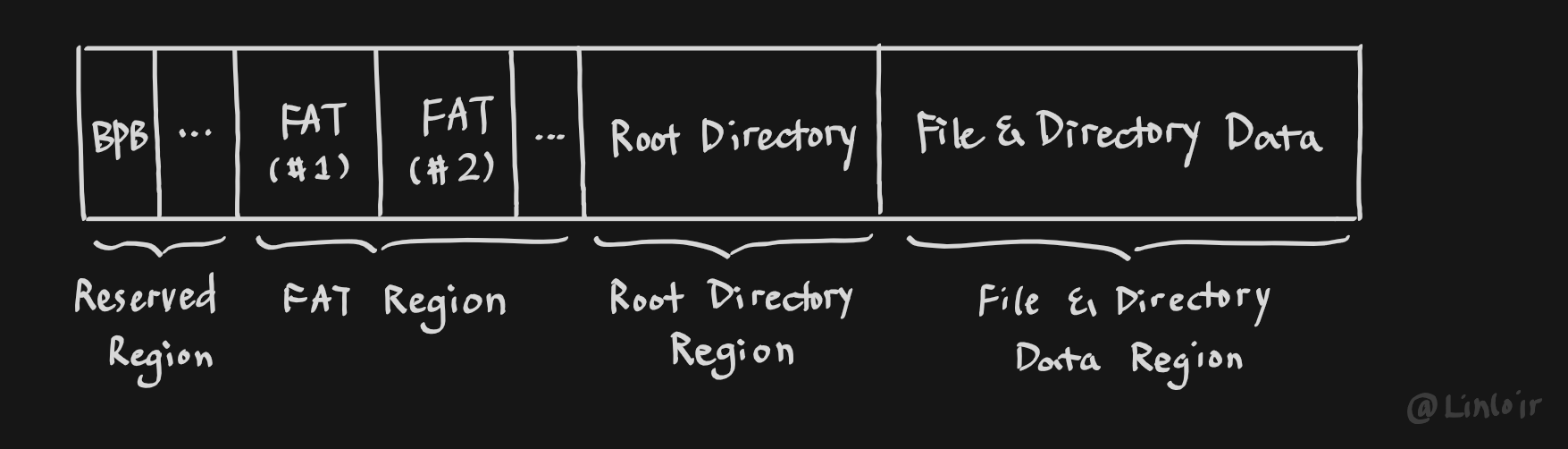
陷阱:小端模式
由于所有的FAT文件系统都是为IBM PC机器的架构所设计,因此其数据结构在硬盘上的存储方式都是小端模式。
BPB数据结构
在FAT格式的卷的首扇区,有一个叫做BPB (Bios Parameter Block) 的数据结构,其主要存储了关于当前卷上FAT文件系统的关键信息,包括了文件系统各个区域的首扇区号,以及簇大小等等。
注:
首扇区并不是所有的内容都属于BPB结构体的范畴,在后续的介绍中,以 BPB_ 开头的域才是属于BPB结构体的域
In the following description, all the fields whose names start with BPB_ are part of the BPB. All the fields whose names start with BS_ are part of the boot sector and not really part of the BPB.
对于FAT12/16和FAT32,它们的BPB结构在首36字节上完全一致:
| 域名称 | 偏移 | 大小 | 描述 | 限制 |
|---|---|---|---|---|
| BS_jmpBoot | 0 | 3 | 跳转到启动代码处执行的指令 由于实验中启动代码位于MBR,不会从这里进行启动,因此可以不用关心这个域实际的内容 |
一般为0x90**EB或是0x****E9 |
| BS_OEMName | 3 | 8 | OEM厂商的名称,同样与实验无关,不需要关心 | - |
| BPB_BytsPerSec | 11 | 2 | 每个扇区的字节数 | 只能是512、1024、2048或4096 |
| BPB_SecPerClus | 13 | 1 | 每个簇的扇区数量 | 只能是1、2、4、8、16、32、64和128 |
| BPB_RsvdSecCnt | 14 | 2 | 保留区域的扇区数量 可以用来计算FAT区域的首扇区位置 |
不能为0,可以为任意非0值 可以用来将将数据区域与簇大小对齐(使数据区域的起始偏移位于簇大小的整数倍处) |
| BPB_NumFATs | 16 | 1 | FAT表数量 | 一般为2,也可以为1 |
| BPB_RootEntCnt | 17 | 2 | 根目录中的条目数 指根目录中包含的所有的条目数量,包括有效的、空的和无效的条目 可以用来计算根目录区所占用的字节数 |
FAT32: 必须为0 FAT12/16: 必须满足 |
| BPB_TotSec16 | 19 | 2 | 16位长度卷的总扇区数 对于FAT32和更大容量的存储设备有额外的BPB_TotSec32域 应当是为了维持BPB结构的一致性而仍然保留了这个域 |
FAT32: 必须位0 FAT12/16: 如果总扇区数小于0x10000(也就是能用16位表示)则使用此域表示,否则也使用BPB_TotSec32域 |
| BPB_Media | 21 | 1 | 似乎是设备的类型 与实验无关,所以可以不用特别关心 |
合法取值包括0xF0、0xF8、0xF9、0xFA、0xFB、0xFC、0xFD、0xFE和0xFF本地磁盘(不可移动)的规定值为 0xF8可移动磁盘的往往使用 0xF0 |
| BPB_FATSz16 | 22 | 2 | 单个FAT表占用的扇区数 只用于FAT12/16格式的文件系统 |
FAT32: 必须为0 FAT12/16: 正整数值 |
| BPB_SecPerTrk | 24 | 2 | 每个扇区的磁道数 与 0x13中断相关只与具有物理结构(如磁道、磁盘等)并且对 0x13中断可见的存储介质有关与实验无关,可以不用关心 |
- |
| BPB_NumHeads | 26 | 2 | 磁头数量 同样与 0x13中断相关,实验不会使用,所以可以不用关心 |
- |
| BPB_HiddSec | 28 | 4 | 分区前隐藏的扇区数 在文档中描述这个域为同样只与对 0x13中断可见的存储介质有关,但在实验过程中发现对于一个多分区的磁盘,这个域对应了分区首扇区在整个磁盘中的扇区号,例如首扇区位于磁盘2048扇区(从0开始计算分区号)的分区,其BPB_HiddSec域值就为2048 |
- |
| BPB_TotSec32 | 32 | 4 | 32位长度卷的总扇区数 用来描述FAT32卷中的总扇区数或是扇区数多于0x10000的FAT12/16卷中的总扇区数 |
FAT32: 必须为非零整数值 FAT12/16: 如果扇区数大于0x10000,则为扇区数,否则必须为0 |
从第37字节开始,FAT12和FAT16卷上的BPB结构如下:
| 域名称 | 偏移 | 大小 | 描述 | 限制 |
|---|---|---|---|---|
| BS_DrvNum | 36 | 1 | 用于0x13中断的驱动器号,可以不用关心 |
应当设置为0x80或是0x00 |
| BS_Reserved1 | 37 | 1 | 保留位 | 必须为0 |
| BS_BootSig | 38 | 1 | 用来检验启动扇区的完整性的签名,可以不用关心 | 如果BS_VolID、BS_VolLab和BS_FilSysType三个域都存在有效的值 (present),则置为0x29 |
| BS_VolID | 39 | 4 | 卷的序列号,可以不用关心 | - |
| BS_VolLab | 43 | 11 | 卷标,可以不用关心 在文档中,要求与根目录下的卷标描述文件保持内容一致,但实际上在测试中往往卷标描述文件中存储的是真实的卷标而这个域的内容仍为缺省值"No NAME" |
缺省值为"NO NAME" |
| BS_FilSysType | 54 | 8 | 用来描述文件系统类型,但不能用来作为判断文件系统类型的依据 | “FAT12”、“FAT16"或是"FAT32” |
| - | 62 | 448 | 空余,置零 | 必须为0 |
| Signature_word | 510 | 2 | 校验位 | 设置为0xAA55 |
| - | 512 | * | 如果则存在此域,全部置零 | 必须为0 |
相对的,从37字节开始,FAT32文件系统中BPB的结构如下:
| 域名称 | 偏移 | 大小 | 描述 | 限制 |
|---|---|---|---|---|
| BPB_FATSz32 | 36 | 4 | 单个FAT表占用的扇区数 只用于FAT32格式的文件系统 |
非负整数值 |
| BPB_ExtFlags | 40 | 2 | 标志位 | [0:3]: 活动FAT表的标号(按照从零开始计数)[4:6]:保留位[7]:当FAT在运行时会自动镜像写入其他FAT表时,置零,否则对于只有一个活动的FAT表时置位 |
| BPB_FSVer | 42 | 2 | 奇怪的版本号域,文档中写了半天描述最后要求置零… | 必须为0 |
| BPB_RootClus | 44 | 4 | 根目录的首簇簇号 | |
| BPB_FSInfo | 48 | 2 | FSInfo结构体所在的首扇区号 |
一般为1 |
| BPB_BkBootSec | 50 | 2 | 备份启动扇区的扇区号 由于现在的硬盘不像当年软盘那样易失,所以关于备份相关的域实际都可以不用关心,因为用不上 |
设置为0或6 |
| BPB_Reserved | 52 | 12 | 保留位 | 必须为0 |
| BS_DrvNum | 64 | 1 | 用于0x13中断的驱动器号,可以不用关心 |
应当设置为0x80或是0x00 |
| BS_Reserved1 | 65 | 1 | 保留位 | 必须为0 |
| BS_BootSig | 66 | 1 | 用来检验启动扇区的完整性的签名,可以不用关心 | 如果BS_VolID、BS_VolLab和BS_FilSysType三个域都存在有效的值 (present),则置为0x29 |
| BS_VolID | 67 | 4 | 卷的序列号,可以不用关心 | - |
| BS_VolLab | 71 | 11 | 卷标,可以不用关心 在文档中,要求与根目录下的卷标描述文件保持内容一致,但实际上在测试中往往卷标描述文件中存储的是真实的卷标而这个域的内容仍为缺省值"No NAME" |
缺省值为"NO NAME" |
| BS_FilSysType | 82 | 8 | 用来描述文件系统类型,但不能用来作为判断文件系统类型的依据 | “FAT12”、“FAT16"或是"FAT32” |
| - | 90 | 420 | 空余,置零 | 必须为0 |
| Signature_word | 510 | 2 | 校验位 | 设置为0xAA55 |
| - | 512 | * | 如果则存在此域,全部置零 | 必须为0 |
文档在接下来的部分介绍了如何初始化一个FAT卷,由于目前只需要读取FAT卷,所以可以忽略章节3.4。
在3.5章节中文档就介绍了如何在装载卷时判断FAT的类型,其中关键的判断算法为
1 | if(CountofClusters < 4085) { |
也就是说,FAT的类型只与簇的数量有关,而与磁盘的大小、扇区数量,包括BPB中的BPB_FilSysType域都无关,其中
- FAT12不能有超过4084个簇
- FAT16不能有超过65524个簇,也不能少于4085个簇
在明白了BPB的结构之后,就可以开始着手对BPB进行抽象了。
最初我采用了两个不同的类来分别对FAT12/16和FAT32的BPB进行抽象,但这样的问题也是十分明显的,在我不确定FAT实际的类型时我把首512字节视为哪个数据结构都不是很合理。但如果我不通过抽象后的数据结构去解析首512字节,我又没办法判断究竟是那种FAT类型。为了解决这个矛盾,我甚至由引入了一个类来描述FAT12/16与FAT32相同的37字节数据,这就导致代码越来越乱,看起来也让人云里雾里的。
但后来就注意到虽然对于FAT12/16和FAT32,它们在结构上存在一定的不同,但其BPB有效的部分都是首扇区的首512字节(如果扇区大于512字节后面的也仍然填充0,可以忽略)。
同时,BPB需要提供的主要功能也是基本相同的,主要的区别基本都在于域宽是16位还是32位。
如果在函数接口的上不区分FAT12/16和FAT32,只在函数的实现上根据FAT12/16和FAT32的不同从512字节的数据中取出对应需要的域,就可以实现功能的统一,调用函数的代码就只需要关心需要使用FAT的哪种信息,而不需要再关心FAT的类型。
例如,BPB_FATSz16和BPB_FATSz32实质上都是为了提供FAT表的大小,它们是可以统一到一个接口uint32 fatSize()上的,需要关心FAT表大小的代码不需要关心具体是哪种格式的FAT系统,只需要调用fatSize()既可以取得需要的数值,具体的解析操作交给了函数本身去区分和实现。
阅读上表,可以总结出BPB所需要提供的所有接口:
1 | uint16 bytesPerSector(); |
可以注意到,有些函数是只有特定的FAT格式才存在的,这时如果调用者强行调用了一个当前FAT格式不存在的接口,实质上是不安全的,因为这样并不会产生任何错误,同时还会返回一个不确定的值。但这样的弊端比起这种实现的优点而言就显得微不足道了。
更进一步地说,由于调用接口的代码只能是操作系统的代码所调用,而操作系统代码只能由我们所完成,所以我们可以通过主动避免错误的调用来避开这个风险,抑或是,可以在函数内额外判断一次FAT类型,并在不合法的调用处陷入死循环等等,有很多可以解决的方法。
除了解析BPB数据的接口以外,由于BPB主要的作用是计算FAT文件系统各个区域的大小、偏移量等信息,所以也不妨将这部分琐碎的代码纳入类的函数作为接口提供给其他程序:
1 | bool isFAT12(); |
于是,完整的BPB头文件fatbpb.h如下:
1 |
|
具体的函数实现则放在fatbpb.cpp中如下:
1 |
|
FAT
回顾:
如果一个文件大小超过了一个簇,那么用来存储它数据的簇可能在磁盘上并不连续,为了能够将这些分散的簇连起来,文件系统一般会为每一个簇对应一个域用来保存关于它下一个簇的信息,从而就可以如同链表那样将整个文件串联在一起。在FAT中,这些域被集中存储在磁盘的一段空间内,这一段空间就叫做FAT (File Allocation Table)。
对于不同的FAT格式,FAT表中每个条目 (entry) 的大小不同:
- 对于FAT12而言,每个条目长12位
- 对于FAT16而言,每个条目长16位
- 对于FAT32而言,每个条目长32位
这时候就发现了,原来FAT后面的数字就是指代的FAT表中每个条目的长度
FAT条目中可能的存储值及其含义如下,其中MAX指代磁盘中合法的最大的簇号:
| FAT12 | FAT16 | FAT32 | 含义 |
|---|---|---|---|
| 0x000 | 0x0000 | 0x0000000 | 当前条目所对应的簇空闲 |
| 0x000 ~ MAX | 0x0002 ~ MAX | 0x0000002 ~ MAX | 当前条目所对应的簇存在内容,并且条目的值就是下一个簇的簇号 |
| (MAX + 1) ~ 0xFF6 | (MAX + 1) ~ 0xFFF6 | (MAX + 1) ~ 0xFFFFFF6 | 保留的值,不能够使用 |
| 0xFF7 | 0xFFF7 | 0xFFFFFF7 | 当前条目所对应的簇是损坏的簇 |
| 0xFF8 ~ 0xFFE | 0xFFF8 ~ 0xFFFE | 0xFFFFFF8 ~ 0xFFFFFFE | 保留的值,有时也作为指示当前条目所对应的簇是文件的最后一个簇 |
| 0xFFF | 0xFFFF | 0xFFFFFFF | 当前条目所对应的簇是文件的最后一个簇 |
陷阱:FAT32高四位保留
FAT32中的每个条目高四位都是被保留的,所以可以看到上表中FAT32对应的值只有7位。除了在格式化的时候,在其他任何时候设置FAT条目时都不应该更改原先高四位的值。
陷阱:FAT表首两个条目保留
注意到上表中有效的FAT条目值从2开始,因为FAT表中的前两个条目是被保留的。
这也就导致了簇号和实际的簇产生了2的偏移:对于任意簇号,当在磁盘上访问实际的簇时,应当访问第个簇
FAT表中第一个保留的条目(FAT[0])包含了BPB_Media域中的内容,其他的位被设置为1,对于FAT32高四位同样不进行更改。例如,如果BPB_Media的值为0xF8,那么
- 对于FAT12,值为
0xFF8 - 对于FAT16,值为
0xFFF8 - 对于FAT32,值为
0xFFFFFF8
第二个保留的条目(FAT[1])在格式化时会被格式化工具赋一个EOC值(具体用处不明)。对于FAT12而言,由于空间有限,所以并没有额外的标记位,对于FAT16和FAT32而言,Windows系统可能会使用高两位作为脏卷的标记位,其中最高位为ClnShutBit,如果该位置位,则意味着上一次该设备没有被正常卸载,可能需要检查文件系统的完整性;次高位为HrdErrBit,如果该位置位,则标明读写功能正常,如果置0则代表遇到了IO错误,提示一些磁盘扇区可能发生了错误。
由于FAT表相当于一个数组,因此其不需要特殊的抽象。
不过由于FAT12的特殊性,12位长度的数据并不能跟字节对齐,也就是说在FAT12中,一个条目从某个字节的中间开始,所以在根据下标从FAT从取值时可能会稍微复杂一些,在文档中也给出了具体的读取的代码。
由于具体文件的读取在KernelLoader中进行,因此这部分的内容可以留待下一个章节再详细研究。
目录结构
到目前为止,BPB以及FAT表我们都已经清楚了,这样不论是FAT12、FAT16还是FAT32,我们都可以顺利地找到根目录所在的区域并且读取根目录所包含的所有数据了:
- 对于FAT12/16,根据保留区的大小以及FAT的大小可以计算出根目录区的首扇区位置,根据根目录区首扇区位置和根目录区大小就可以读取全部根目录区数据
- 对于FAT32,根据根目录区所在的簇号以及FAT表可以读取全部根目录区数据
那么,接下来就要解决如何解析根目录内的文件了。更广泛地讲,由于根目录就像其他所有的文件目录一样,所以接下来就要解决如何读取一个目录,并且得到目录中各个文件的信息。
实际上,目录同样是一个由目录条目构成的数组,其中每一个目录条目都是一个32字节长度的数据结构,而正是这个数据结构中存储的数据描述了一个目录中存储的文件或是一个子目录的详细信息,例如它的创建日期和时间、名称或是最重要的首簇簇号等等。它的完整结构如下:
| 域名称 | 偏移 | 大小 | 描述 |
|---|---|---|---|
| DIR_Name | 0 | 11 | 短名称格式的文件名 |
| DIR_Attr | 11 | 1 | 文件的属性标记 |
| DIR_NTRes | 12 | 1 | 保留位,必须为0 |
| DIR_CrtTimeTenth | 13 | 1 | 文件创建时间,单位为10ms |
| DIR_CrtTime | 14 | 2 | 文件创建时间 |
| DIR_CrtDate | 16 | 2 | 文件创建日期 |
| DIR_LstAccDate | 18 | 2 | 文件最近访问日期 |
| DIR_FstClusHI | 20 | 2 | 首簇簇号高16位 |
| DIR_WrtTime | 22 | 2 | 文件修改时间 |
| DIR_WrtDate | 24 | 2 | 文件修改日期 |
| DIR_FstClusLO | 26 | 2 | 首簇簇号低16位 |
| DIR_FileSize | 28 | 4 | 文件的大小,单位为字节 |
其中提到了一些概念,如短名称、文件属性以及一些仍然不明确的结构,如日期和时间的表示格式,如果继续阅读,则会发现文档也一一对它们作出了解释。
短名称为一种表示文件名称的格式,其11字节长度的域被分为8字节和3字节的空间,其中11字节用来存储文件不含扩展名的部分,而后3字节用来存储文件的扩展名,在存储名字的时候,所有的字母都会以大写字母的形式存储。
同时,短名称的存储方式会在文件名长度小于最大长度时在其后面填补空格,例如FOO.BAR在存储时由于文件名为三字节,所以会在其后填补5个空格,存储为FOO BAR
除此之外,短名称还遵循以下规则:
- 若首字节为
0xE5则代表当前条目为空 - 若首字节为
0x00则同样代表当前条目为空,并且还代表当前条目之后的所有条目都为空 - 首字节不能为空格,也就是说文件名不能以空格开头
- 目录中不能出现名称相同的两个条目
- 不能出现小写字母
- ASCII值小于
0x20的字符以及0x22、0x2A、0x2B、0x2C、0x2E、0x2F、0x3A、0x3B、0x3C、0x3D、0x3E、0x3F、0x5B、0x5C、0x5D、0x7C
然而,如果文件名称很长的话,短名称就显得不太够用了,所以FAT还额外提出了长名称的解决方案,并且称存储短名称的条目为 SFNEntry,长名称的目录为 LFNEntry。
在长名称的解决方案中,一个文件会对应一个短名称的条目和一系列长名称的条目,短名称条目存储文件名称的前数个字符和扩展名,而长名称则存储文件的全部名称。
在目录中,一个文件对应的长名称条目和短名称条目连续存储,其中地址从低到高依次存储:
- 第N个长名称条目
- 第N-1个长名称条目
- …
- 第1个长名称条目
- 短名称条目
其中,长名称条目的结构如下:
| 域名称 | 偏移 | 大小 | 描述 |
|---|---|---|---|
| LDIR_Ord | 0 | 1 | 当前条目在当前文件所有长名称条目中的顺序,从1开始计数 如果是最后一个条目,则需要额外置位 0x40 |
| LDIR_Name1 | 1 | 10 | 存储当前条目中文件名的第1~5个字符 |
| LDIR_Attr | 11 | 1 | 文件的属性标记,与短文件名条目的属性标记域保持相同含义 对于长文件条目,所有的属性位都应被置位 也即 ATTR_READ_ONLY | ATTR_HIDDEN | ATTR_SYSTEM | ATTR_VOLUME_ID |
| LDIR_Type | 12 | 1 | 必须为0 |
| LDIR_Chksum | 13 | 1 | 校验位,用于校验当前条目是否与文件对应的短文件名条目相匹配 |
| LDIR_Name2 | 14 | 12 | 存储当前条目中文件名的第6~11个字符 |
| LDIR_FstClusLO | 26 | 2 | 必须为0 |
| LDIR_Name3 | 28 | 4 | 存储当前条目中文件名的第12~13个字符 |
陷阱:LDIR_Ord从1开始
文件对应的第一个长文件名条目在集合中的序号为1,而不是0
陷阱:长文件名使用Unicode存储
长文件名中的LDIR_Name1、LDIR_Name2和LDIR_Name3中存储的都是Unicode格式的文件名,一个字符占据两个字节。
对于校验码,文档也提供了算法,对应到实验中的实现为:
1 | //Calculate/Return the checksum of the entry |
文件的属性使用按位枚举的方式表示,其中的六个二进制位分别如下:
| 属性 | 位 | 描述 |
|---|---|---|
| ATTR_READ_ONLY | 1 << 0 | 文件只读 |
| ATTR_HIDDEN | 1 << 1 | 文件隐藏 除非用户或程序显式声明要求访问隐藏的文件,否则不应当在文件列表中被列出 |
| ATTR_SYSTEM | 1 << 2 | 文件为系统文件 除非用户或程序显式声明要求访问系统文件,否则不应当在文件列表中被列出 |
| ATTR_VOLUME_ID | 1 << 3 | 文件用来描述卷标 |
| ATTR_DIRECTORY | 1 << 4 | 文件实际上是一个目录 |
| ATTR_ARCHIVE | 1 << 5 | 当文件被创建、重命名或修改时置位,指示文件是否被修改过 |
陷阱:卷标文件只能出现在根目录
卷标文件为根目录中描述卷标的特殊文件,其DIR_NAME域全部用来存储卷标,同时属性域为0x8,也即ATTR_VOLUME_ID,其他部分均为0。
文件的日期和时间有特殊的存储格式
其中文件的日期包括三个部分:
[4:0]:日(从1至31)[8:5]:月(从1至12)[9]:从1980年起的年份偏移(从0至127)
文件的时间同样也包括三个部分:
[4:0]:从零起经过的2s间隔数(从0至29)[10:5]:分(从0至59)[15:11]:时(从0至23)
可以看到,秒的精度为2s,这也就引出了CrtTimeTenth这个域,其精度为10ms,范围从0至199,正好填补了2s之间的空缺,使得精度提高到10ms
在了解了目录的结构之后,就可以着手对目录进行抽象了。由于目录本身还是相当于关于目录条目的数组,所以根本在于对目录条目进行抽象。
因为目录条目分为SFN(短文件名)和LFN(长文件名)两种类型,但其总长度一样,所以可以参考对BPB进行抽象的过程:将两种条目合并在一起,均视为DirEntry类,在调用具体函数的时候再根据条目类型的不同执行不同的判断。
其中,由于文件属性的域涉及到位枚举,而C++没有原生支持位枚举,所以需要我们手动先在头文件中实现位枚举:
1 | class DirectoryFlag { |
并在.cpp文件中给出重载操作符的实现
1 | DirectoryFlag::DirectoryFlag() { |
之后就可以根据上述表格完成DirEntry类的定义和实现了。需要注意的是,由于要从跟日期和时间有关的域中解析出对应的年月日或是时分秒仍然需要一步操作,所以我将条目中用到的时间和日期又额外包装成FATDate和FATTime放在fatdt.h中,并在这两个类中提供解析出年月日和时分秒的接口,在DirEntry的接口中不在返回裸的数值,而是将其转换为这两个类的实例进行返回。
我所实现的fatdt.h文件内容如下:
1 |
|
关于具体函数的实现,就留给读者自己完成。
综上,可以完成fatdir.h文件如下:
1 |
|
完整的fatdir.cpp则实现如下:
1 |
|
抽象MBR结构
上一小节中,我们实现了FAT文件系统的抽象,为从文件系统中读取内核文件奠定了基础。对于一个仅有一个分区的硬盘而言,如果其文件系统恰是FAT格式,那么就可以使用我们抽象出的接口访问其中的文件。
但现如今磁盘中只有一个分区的电脑少之又少,如果磁盘中有多个FAT格式的分区,那么加载程序应该去哪个分区寻找内核文件,又该如何定位到对应分区的位置呢?
这些就要依赖于存储在MBR中的数据了。在第二章:计算机是如何启动的一节中提到,MBR在447~510这64个字节中存储了分区表信息,包括了分区的引导标志、起始磁道、起始扇区、起始柱面等信息。
注:实验中使用的是MBR分区表
在实验中使用的是MBR分区表,而不是GPT分区表,所以通过MBR来解析分区信息。
在MBR分区表下,最多只能存在四个主分区,这是由MBR存储分区表区域的空间限制所导致的,更多的分区则需要使用逻辑分区来表示,关于逻辑分区的内容与本次实验无关,故此处不进行介绍。
通过这些特殊的信息,加载程序就可以判断哪个分区是活动的,以及这个分区在磁盘上的位置,以及分区上文件系统的类型。在确定了这些信息之后,加载程序就可以使用上一节中关于文件系统的接口来读取和加载内核文件了。
在经历了对文件系统的抽象之后,此时大家应该很快就能想到,为了能够方便地解析MBR中分区表的数据,可以对MBR的结构进行抽象。
MBR结构
参考资料:MBR结构
关于MBR结构的详细信息,此文中参考了 Wikipedia中关于MBR的页面 ,其中,实验采用了Classical generic MBR的格式对MBR结构进行解析。
在最一般的MBR结构中,其包含了三个主要的部分:
- 计算器启动代码 (Bootstrap code):这部分空间用来存储计算机启动后要执行的第一段操作系统代码,也就是我们在第二章中实现的用来启动BootLoader的代码
- 分区表 (Partition table):这部分空间由四个分区目录条目 (Partition entry) 组成,用来描述磁盘中的分区信息
- 启动签名 (Boot signature):一般为
0xAA55,用来向BIOS表示磁盘是可启动的
它们的地址和大小如下:
| 内容 | 起始地址 | 大小 |
|---|---|---|
| 启动代码 | 0x0000 | 446B |
| 分区条目1 Partition entry №1 |
0x01BE | 16B |
| 分区条目2 Partition entry №2 |
0x01CE | 16B |
| 分区条目3 Partition entry №3 |
0x01DE | 16B |
| 分区条目4 Partition entry №4 |
0x01EE | 16B |
| 启动签名 | 0x01FE | 2B |
Partition Entry结构
同时,每个分区条目 (Partition entry) 又具有如下的结构:
| 偏移 | 大小 | 描述 |
|---|---|---|
| 0x00 | 1 | 描述分区的状态0x80用来表示活动分区0x00表示非活动分区其他值均为无效值 |
| 0x01 | 3 | 分区首扇区的CHS表示 |
| 0x04 | 1 | 分区的类型 |
| 0x05 | 3 | 分区末扇区的CHS表示 |
| 0x08 | 4 | 分区首扇区的LBA扇区号 |
| 0x0C | 4 | 分区总扇区数 |
其中,根据 Wikipedia上关于分区类型的页面 中的描述,实验中将会用到的分区类型以及它们的值为:
| 类型 | 值 |
|---|---|
| FAT12 | 0x01 |
| FAT16 | 0x04 |
| FAT32(CHS) | 0x0B |
| FAT32(LBA) | 0x0C |
同时,扇区号的CHS表示又具有如下的结构:
| 偏移 | 大小 | 描述 |
|---|---|---|
| 0x00 | 1 | 磁头号 (head) |
| 0x01 | 1 | 由两部分组成: 高2位为柱面 (cylinder) 第8-9位 低6位为扇区号 (sector) 第0-5位 |
| 0x02 | 1 | 柱面 (cylinder) 第0-7位 |
可见,对于一个分区条目而言,其主要的作用就是判断分区是否存在、判断分区的状态(是否是活动分区)、标记分区的文件系统类型以及获取分区的首扇区号和扇区数,因此其接口就主要围绕这些方面进行设计:
1 | public: |
抽象Partition Entry
明确了分区条目的结构和需要提供的接口,可以迅速将分区条目抽象为Partition类型如下:
1 | class Partition { |
上述接口则均实现在partition.cpp文件中:
1 |
|
同时,在分区条目的结构中涉及到的CHS扇区号由上文中提到的CHS结构抽象为CHSAddress类型,其只需要提供从3字节长度的数据中提取柱面、磁头和扇区号的接口:
1 | class CHSAddress { |
注:
由于在实验中实际上并不会通过CHS的地址来计算扇区号,因此在实验中并没有对这三个接口进行具体的实现,这部分内容就留给读者完成。
抽象MBR
实现了对分区条目的抽象之后,对MBR结构的抽象就易如反掌了,因为其实际上就是由一段长度为446的字节数组 (Bootstrap code) 、四个分区条目类型的对象 (Partition table) 以及一个两字节的数组 (Boot signature) 组成的:
1 | //mbr.h |
由于Partition类型的对象已经提供了足够使用的接口,因此MBR并不需要再设计额外的接口,而只需要将四个Partition的变量暴露给程序即可。如果程序想要从MBR中获得一个分区是否是活动的,以及其起始的LBA扇区号,其可以进行如下的操作:
1 | //Assume there is a MBR typed variable mbr |
抽象页表
实现了MBR和文件系统的抽象就意味着现在我们已经可以从硬盘中找到需要的内核文件了,并且借助硬盘读取的接口将内核的文件从硬盘中读取到内存。下一步就是将内核加载到正确的地址空间中,完成加载内核的全部步骤。但是在开始加载内核之前,需要先了解虚拟内存的概念以及分页机制的原理,并且实现对分页要用到的数据结构进行抽象后才能正确地对内核进行加载。
简述虚拟内存与分页机制
参考资料
如果想要了解关于内存管理策略以及虚拟内存的全部内容,可以阅读课本《操作系统概念》中第三部分关于内存管理的内容,我强烈建议先完成这部分的阅读再继续后面的实验。
当然,在接下来的相当一部分篇幅中,我也会用我自己的理解介绍什么是虚拟内存,以及分页机制的最基本概念。但这些远不如书本全面、权威,因此再次建议大家先对课本进行一次略读后再继续后面的实验内容。
既然要介绍虚拟内存和分页机制,自然就要从它们出现的原因谈起,而这就绕不开 “程序是如何运行起来的” 这个话题。
在学完了『操作系统原理』这门课后,想必已经对程序的运行有了一个大致的认识,知道了程序运行的基础是CPU对机器指令的执行,而CPU执行机器指令由是由数个流水级逐步完成的,不考虑分支预测等等复杂的实现,CPU对指令的执行可以抽象为以下的步骤:
- 存储指令地址的存储器(可以视作PC)提供了一个地址信号输入存储指令的存储器(在这里就是内存了)
- 内存根据输入的地址信号在下一个时钟沿输出对应地址空间上存储的指令
- 其他流水级完成指令的解析等,同时指令地址完成一次自增
可见,想让程序运行起来,关键就是两步:
- 把指令存到内存中
- 把指令的地址放置到存储指令地址的存储器(PC)中
这样,在下一个时钟周期到来的时候,CPU就会从想要执行的指令处开始执行了。
把指令的地址放置到PC中就十分简单了,在汇编中常见的跳转指令都可以完成这一操作,在硬件上的实现想必大家也是历历在目的(小声),那剩下还要解决的就是把指令存到内存中这个问题啦。
但偏偏就是把指令存到内存中这么一个看起来很简单的操作,背后却暗藏了各种难题,为了这么一个操作,曾经的工程师们也可谓是八仙过海,各显神通。
还记得我们在第二部分:从代码到可执行文件一节中提到的程序的链接步骤中提到,在链接时需要指定程序起始的地址,这个地址关系到了整个程序所有代码段中使用到的绝对地址的计算,这就为程序的加载带来了一个大难题:
如果我不知道程序要加载到哪里,那我应当如何指定程序起始的地址?
如果强行提前指定了程序的起始地址,那个地址被其他的程序占用了又该怎么办?
于是,曾经伟大的工程师们就提出了一个概念:让程序视角下的地址和它真正运行着的地址分开。通俗点解释,就是令程序在执行的时候中,其指令中的各种地址都视为程序视角下的地址,通过一些手段,让这个地址和真正访问内存的地址不是同一个地址,但又存在着一定的映射关系:
结合才学没多久的计算机组成原理课程的知识,可以大致理解为,在从指令中分离出地址后并不是直接送入内存,而是经过一个特殊的地址变换部件 (这也就是常说的MMU) 之后才会送入内存。
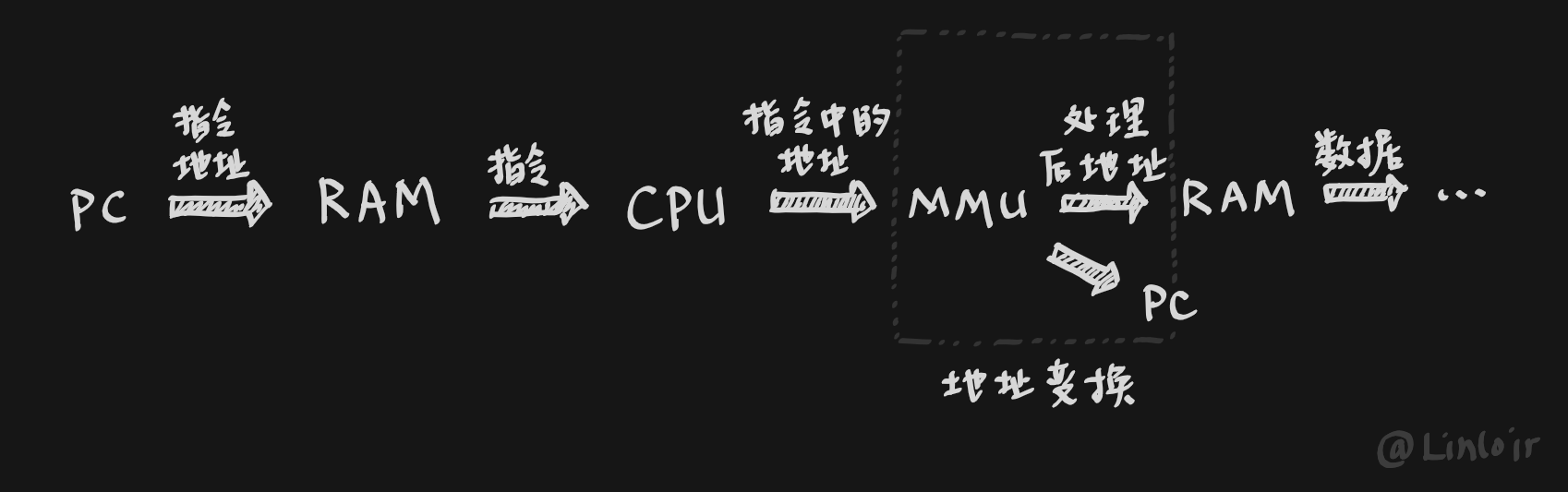
什么是程序视角下的地址:
就像上图,当程序在运行的时候,CPU会根据指令生成出一些地址的值,例如mov eax, dword [ebx]会从内存中加载4字节数据,其产生的地址是ebx中存储的值;或是jmp 0x7E00会跳转到0x7E00处执行,CPU会产生0x7E00这个地址送入指令地址寄存器。
然而,CPU所不断地产生出的地址的值,还需要经过地址变换部件才能成为有意义的地址。对于CPU而言,它并不知道MMU的存在,它只知道指令生成了一些地址,而且在运行的过程中这些地址确实产生了正确的效果,看起来就像是程序真的就放在这个地址上运行一样,而不知道这些地址实际上是由于MMU的地址变换作用才产生了正确的效果,所以这实际上这些未经变换都可以被称作是CPU“假想”的地址,也就是常说的虚拟地址,我个人喜欢将它们称为是程序视角下的地址,我认为这样说会更形象、更易于理解。
由于程序的视角其实通俗理解就是CPU的视角,所以在程序执行过程中由CPU生成的地址,其实就是程序视角下的地址。
这些地址是虚拟的,是假定的,因为它们并不能代表程序在内存中存放的地址,这一点很重要。
陷阱:程序某个部分在内存中的地址≠程序视角中这个部分的地址
要理解后面的分页制度,就一定要有程序视角的地址是“假想”的地址,是程序所认为的它在内存中的位置的概念。
在出现了地址变换部件这个概念之后,程序在运行的时候由CPU生成的所有地址都不再一定是CPU想要从内存中获取的数据的地址,而是要经由一次MMU的映射才能获得程序想从内存中获取的数据的地址。
这样,即便程序都以0x0为起始地址,也可以通过不同的地址变换方式来达到将程序存储在内存中不同位置的效果。
但是摆在工程师面前的,还有更多的问题:
如何从空闲的空间中选择合适的位置存储需要加载的程序?
在操作系统运行的过程中,会不断有程序需要被加载到内存运行,同时也会不断地有程序结束运行。结束运行的程序可以释放出它本身占用的空间,需要加载运行的程序则需要申请能够存放其自身的空间。如此往复的过程中,不断被申请然后被释放的程序所占用的内存空间会让内存的地址空间中出现一个个的空洞 (Hole),原先连续的大片空闲区域就这样被分割成了不连续的许多小的空闲的内存片段:
这听起来就不是什么好事,事实上也确实是如此,当操作系统要加载一个新的程序进入内存的时候,它几乎一定面对的是一个“满目疮痍”的内存空间,而如何从无数的空洞中选择合适的那个来存放程序,也就成了一个难题。过去的工程师提出了三种解决方案:
- 最优适应:一种强迫症式的挑选方法,非得找到所有足够装下程序的空洞中最小的那个,在欧皇时刻这样挑恰好就能放进去,但是非酋时刻则会产生一个非常小的空洞,导致最后谁都放不进去,白白浪费。
- 最差适应:一种走极端的挑选方法,你说最优适应会产生小空洞让谁都放不进去,那行,我就找到所有足够装下程序的空洞中最大的那个,在这种情况下,一般剩下来的空洞还是能够再利用的。
- 首次适应:一种摆烂式的挑选方法,只要找到了能装下的空洞,啥也不管了,冲就对了,奥里给!但你说妙不妙,这样的策略竟然反倒在空间和时间方面都胜最差适应一筹,和最优适应难分伯仲,甚至还更快些!
再次证明了开摆就对了!
碎片:
在上面的描述的三种为程序的分配内存的方式中可以看出并不是每一次都能够为程序分配恰到好处的空间,往往一个新程序的加载会导致内存中出现小的空洞,这些空洞小到几乎不足以放下任何其他的程序,这就意味着这部分内存直到程序运行完毕被释放之前都不能够被操作系统用来为其他程序分配,这些实际上被浪费掉的内存空间就是碎片。
碎片又分为外部碎片和内部碎片,前述的这种在为程序分配的空间以外的浪费空间叫做外部碎片,而如果操作系统为一个程序分配了多余它实际要使用的内存空间,那么其内部被浪费掉的空间就叫做内部碎片,这种类型的碎片将会在后面介绍分页机制时看到。
碎片对于内存空间的利用而言是致命的,试想一个充满了碎片的内存,明明其空闲的空间足够大,但是由于全部都是由碎片组成,而不能放入任何一个程序。
然而,上面的三种分配方式都仍然是将一个程序视为一个整体进行加载的,多少有点偏执了。
假设内存中有 个大小为 大小的空洞,需要加载一个大小为 大小的程序,此时不论采用上述哪一种分配方式,都无法找到任何一个合适的空洞来装载新的程序。如果此时摒弃非要把一个程序连续装入内存的落后思想,而是想办法把程序剁成四块,分别为 、 、 和 ,然后装入四个空洞中,不就成了吗?
聪明的工程师自然也想到了,所以分页的概念也就应运而生。
为了方便操作系统进行管理,工程师将内存和程序都按照一个相同的大小进行分割,例如常见的 ,这个固定大小的空间就叫做页,将内存和程序分割的过程也就叫做分页。
对于内存而言,剩余不足一页的空间会被舍弃;对于程序而言,不足一页的部分也会分配一个完整的页,这时页中没有被使用的部分就是内部碎片,例如如果程序的大小为 ,而页的大小为 ,则程序会占用两个页,即使第二个页中只有一个字节是真正被使用的,这就产生了 的内部碎片。
陷阱:对程序分页实质上是对程序地址空间进行分页
对程序分页是指的对程序视角下的地址空间进行分页,而不是对程序实际在内存中占用的地址空间进行分页,并且这之中还有一个先后的关系,程序只有先对它所用到的地址空间进行分页,才能对应地放入到内存中分好的页里。
物理页和虚拟页:
在后文中,物理页就将指代内存中的页,而虚拟页就将指代程序的虚拟地址空间中的页。
在内存进行了分页之后,往后内存空间的分配和释放都会以一页为最小单位,因此当需要加载新的程序进入内存时,如果内存中空闲的页不少于程序运行所需要的页,则为程序分配其所需要的数量的页,并且建立一个从程序视角下的页到实际内存中的页的映射关系
有了这样的映射关系,操作系统就可以对应着将程序的内容装载进内存,至于在程序视角下的地址空间内那些空间需要写入内存、怎样写入内存等等将会留到下一小节介绍。
但是这样复杂的映射关系,CPU是如何记住的呢?
这就要提到本章节的主角页表了。为了能够让MMU知道程序视角下的页与内存中页的映射关系,早期的工程师创造了一个类似FAT表的表结构,其中每个程序视角下的页都可以对应到一个表项,而每个表项中的内容都对应到一个内存中的页,这个对应关系使用内存页的首字节地址表示。
不过CPU产生的地址肯定不会是页的大小的整数倍,而是可能对应着一个页内的任何一个字节,此时如果只有页的映射关系是否有些不够了呢?
自然不是的。由于页在映射的时候是将一个页视为一个整体进行映射,所以同一个内容在虚拟页和物理页中的偏移量是相同的,在对CPU生成的地址进行变换的时候,只需要将页的地址和偏移量分离开来,通过页表得到物理页的地址以后,再将其作为基址叠加上原先分离出的偏移量,就可以得到映射后的地址了。
不过,只是得到虚拟页的首字节地址还不够,既然要在页表中寻找对应关系,就需要知道虚拟页对应的下标,也就是虚拟页在所有页中的序号。由于页的大小都是 形式,所以第 个虚拟页的地址有如下关系:
所以对于一个虚拟页,其在页表中的下标就可以通过虚拟页的地址移位得到。对于大小为 的页,一个虚拟页对应的下标为
代入上式可得
以 大小的页为例,对于虚拟地址0xC00002a0,其高20位0xC0000代表这个地址所在的页的序号,而低12位0x2a0其实是代表着这个地址在页内部的偏移量。也即在程序的虚拟地址中,0xC00002a0地址位于第0xC0000页中第0x2a0个字节处。访问页表中下标为0xC0000的项,得到虚拟页对应的物理地址,例如0x20000000,再将物理地址和偏移量合并,得到映射后的物理地址0x200002a0。
不过,如果按照这样的方式映射,对于一个32位的系统来说,每一个虚拟页都需要4个字节来存储其对应的物理页的地址,而32位的地址最多可以取到 的地址范围,假设页的大小为 ,以 表示 x所占用的内存字节数,那么页表最多需要占用的内存计算如下:
也就是说,光是一个页表结构就要占用 的内存空间,对于现在动辄 的内存来说可能微不足道,但在曾今内存空间寸土寸金的时候,甚至足够跑起一个操作系统内核,这就显得页表有些过于臃肿了。于是,为了解决这个内存占用的问题,工程师们又提出了多级分页 (Multi-level paging) 的概念,其中在32位的操作系统中使用最多的是二级分页 (Two level paging),而64位操作系统多使用四级分页或是更多级别的分页。尽管分页的级数会存在不同,但它们的原理都是相同的,而且都是为了解决一个问题:减少页表自身占用的存储空间。
以二级分页为例,实际上就是将原先页表的结构同样按照页划分为块,对于上面提到的32位架构中的页表结构可以被划分为 个块,每一个划分出来的块都叫做一个一级页表 (Level 1 Page Table)。每个原先的页表项此时就可以像虚拟地址那样,表示成为一级页表的序号和页表内的偏移,不过此时的偏移就不是以字节为单位的偏移,而是以页表项元素大小(4字节)为单位的偏移。
对于一个原先页表项的序号 ,它对应的一级页表的序号和页表内的偏移为:
通俗而言,就是原先页表项的下标的高10位为这个页表项所在的一级页表的序号,低10位则为这个页表项在其所在的一级页表中的下标。例如页表中原先位于0x80200(0b1000_0000_0010_0000_0000)的页表项,可以认为是在第0x200(0b10_0000_0000)个一级页表中的第0x200个页表项。
在划分了一级页表之后,额外添加了一个页表,其中的每一项是32位的数值,指向这一项下标对应的一级页表所在的首字节的地址,这个页表就是二级页表 (Level 2 Page Table)。由于在32位架构的设备上最多有 个一级页表,而一个一级页表对应的二级页表中的页表项大小为4字节,所以二级页表的大小为
正好就是一个页的大小。
这样,当要将一个虚拟地址转换为物理地址时,需要
- 取低12位为页内偏移
- 取中10位为一级页表内页表项的下标
- 取高10位位二级页表内页表项的下标
- 使用二级页表项的下标在二级页表中取得一级页表的地址
- 使用一级页表项的下标和一级页表的地址取得虚拟地址对应的物理页的地址
- 根据物理页的地址和页内偏移得到转换后的物理地址
乍一看,好像二级页表的出现是多此一举,本来可以直接用下标在页表里定位到页表项,从页表项直接取得物理页地址,现在还要多此一举,先从二级页表拿到一级页表的地址,然后才能拿到物理页地址。仔细一算的话,对于所有的虚拟页都进行映射的情况,二级分页甚至还要比不采用二级分页多出一个二级页表的大小,这哪里节约了页表占用的空间!
最初我也是同样对此感到十分地疑惑,一个不但增加了内存占用,复杂了流程还减慢了地址转换地速度的方案怎么就流传下来了呢?后来我意识到我忽略了一个很关键的细节:前文中讨论页表占用的内存是时始终是基于虚拟地址全部映射到物理地址这个前提进行的,然而事实上,大部分时候都不会需要将虚拟地址全部映射在内存中,甚至有时候内存根本就不够映射全部的虚拟地址!
虚拟地址不完全映射到内存就意味着页表中有空的页表项,对于没有二级分页的方案,由于整个页表都相当于一个巨大的数组结构,即使一个元素为空也不能舍弃它的空间,所以不论映射了多少虚拟页,页表占用的大小始终是固定的。然而对于二级分页的方案,由于二级页表记录的是一级页表的地址,这也就相当于拆散了原先巨大的页表,并且还使得拆分后得到的一级页表可以分散地存储在内存中。这样做还带来了一个巨大的好处,就是页表的内存不再需要一次性分配完毕,因为原先没有多级分页机制的时候,但凡需要页表,就需要一次性申请全部页表的空间,而现在即便一级和二级页表还是相当于数组结构,还是需要为每一个页表分配固定大小的内存,但是它们单个的体积从原先的 降到了 ,同时由于二级页表的存在,如果一整个一级页表内的表项全部为空,那么就可以不分配这个一级页表的空间,从而达到节省空间的目的。
有了二级页表之后,现在摆在我们面前的只剩最后一个问题:
如果程序代码比内存还要大怎么办?
早期的RAM相当金贵,远不及如今动辄16GiB、32GiB,能有个几兆几十兆都是奢侈。那如果一个程序就十分不巧,大小竟然比内存还大,那这个庞然大物该如何运行起来呢?
这就要提到一个叫做 程序运行的局部性原理 的概念,它是指程序在一段时间内程序的执行只限于程序的一部分,就以我们熟悉的冒泡排序算法为例吧:
1 | for(int i = 0; i < n; i++) { |
即便程序的其余部分无比复杂,哪怕是3A巨制,但只要程序运行到这里,它在相当一段时间里只会在两个for循环里打转转,它访问的内存也只会局限在arr这个数组里,这就是程序的局部性,在这一段时间里程序所用到的空间就是程序所需要的工作集。
由于程序运行具有局部性的原理,所以不论程序占用的虚拟地址空间有多大,它在一个特定的时间长度内都不会访问全部的地址空间,这时只需要将其运行需要的部分加载到内存中,程序就可以正常地运行了。这就好比我们在玩Minecraft时候,往往我们的视野半径只有十几个区块,所以加载无尽的世界的所有区块(这显然是不可能的!)和只加载我们视野范围内的区块在我们看来效果是一样的(甚至肯定会流畅不止一点点),所以为了能让我们愉快的玩上游戏,游戏的设计者就不会让电脑加载视野范围外的区块,或者是限制加载视野范围外的区块,从而让我们体验不变的情况下让游戏能够正常地运行,电脑不至于直接冒烟。
抖动
即使程序运行具有局部性,但仍可能出现工作集比内存大小大的情况。
比如一个程序在某一时刻的工作集为10个页ABCDEFGHIJ,而内存只有9个页可供程序使用。
假设某一时刻程序加载了ABCDEFGHI页,当它需要J页的时候,其发现页并不在内存中,就会尝试从磁盘加载这个缺失的页进入内存。
而这个操作就会顶掉ABCDEFGHI中的一个页,很快,程序又会遇到被顶掉的页,其又会加载并顶掉另一个页。
这样的操作会如此不断重复,程序也就无法再正常地继续运行了,这就是抖动现象。
抽象页表数据结构
现在,我们知道了什么是虚拟地址,什么是分页,什么是多级分页。在实验中我们要用到的就是上文中提到的二级分页机制,它用到了一级页表、二级页表和其中的页表项三个主要的数据结构,而一级页表和二级页表实质都是页表项的数组,没有本质上的差异,可以视为同一个数据结构,所以我们只需要实现页表和页表项的数据结构就足够使用了。
由于页表中需要用到页表项,所以我们首先来对页表项 (PageTableEntry) 进行抽象。
前文中提到,页表项中存储的是一级页表或是物理页的地址,其实这个描述不是十分准确。如前文所述,由于页的大小固定,并且都是 的大小,所以任何一个页的地址的低位其实都是相同的且都是0,这就意味着保留着些位是毫无意义的,例如,对于32位的架构而言,由于页的大小为 ,所以任何一个页的地址低12位均为0。工程师显然也发现了这一点,所以它们决定利用这12个无用的位来存储更多的信息,包括页的属性、权限等。
根据 OSDevWiki上关于页表项结构的描述,页表项 (Page Table Entry) 的结构如下:
| 简写 | 全称 | 位 | 描述 |
|---|---|---|---|
| P | Present | [0] |
页表项存在位0:不存在1:存在 |
| R/W | Read/Write | [1] |
写权限位0:不可写1:可写 |
| U/S | User/Supervisor | [2] |
访问权限位0:用户级程序不可访问1:用户级程序可以访问 |
| PWT | Page Write Through | [3] |
写穿透位,实验中不会用到,可以不用了解 |
| PCD | Page Cache Disable | [4] |
禁用缓存位,实验中不会用到,可以不用了解 |
| A | Accessed | [5] |
访问位0:页面在上次清除这个位之后没有被访问过1:页面在上次清除这个位之后被访问过 |
| D | Dirty | [6] |
脏位0:页面在上次清除这个位之后没有被写过1:页面在上次清除这个位之后被写过 |
| PAT | Page Attribute Table | [7] |
用于指示内存缓存类型 (Memory caching type),实验中不会用到,可以不用了解 |
| G | Global | [8] |
全局页面位,使得TLB缓存中的页表项不会随着CR3寄存器的更改而失效,实验中不会用到,可以不用了解 |
| Address | - | [31:12] |
地址高20位 |
尽管在前文的描述中,好像一二级页表中页表项结构是相同的,但实际上它们在某些位的功能上存在一部分差异,这部分差异即使是我自己在实现的时候也忽略了,直到写这一份日志仔细查阅Wikipedia时才发现。在二级页表中,它的目录项第6位、第7位和第8位的含义有所不同,其中第6、8位在二级页表的页表项中作保留位,而第7位的属性描述如下:
| 简写 | 全称 | 位 | 描述 |
|---|---|---|---|
| PS | Page Size | [7] |
页大小位0:页大小为4KiB1:页大小为4MiB在实验中使用4KiB大小的页,所以这一位始终为0 |
为了简便起见,我在实验中采用了不那么安全的实现:我将两种不同的属性合并在同一个位枚举类当中,并在后续的使用中主动避免使用不符合类型的属性。如同在硬盘驱动和FAT中介绍的位枚举类那样,页表项中的属性位可以抽象如下:
1 | class PageFlag { |
对应的实现在复制之前的枚举类函数的基础上对参数类型进行修改,对应_attr变量的类型即可:
1 | PageFlag::PageFlag() { |
接着,就可以抽象页表项的结构了,由上表可以看出,页表项就是由高20位的地址位和低12位的属性位组成。在实现中我选择将整个页表项的值视作一整个变量进行存储:
1 | class PageTableEntry { |
然后再为类添加从值中解析出地址和属性或是根据参数设置值中的地址位和属性位的成员函数:
1 | public: |
为了方便类的实例或是指针的构造,额外添加构造函数和静态成员函数如下:
1 | public: |
小技巧:
在后面的编程实践中,由于我们往往拿到的都是某个页表项的地址,而不是一个页表项的实例。
对于像页表项这样比较复杂的结构,如果直接通过地址和指针的解引用然后再对其中的内容进行解析,则会让代码的可读性变得很差,例如获得页表项中存储的地址可以用uint32 address = (*ptr) & 0xFFFFF000实现。
但由于指针具有可以随意其指向的内容的类型的特性,可以通过将一个指针转换为对应结构的类(例如PageTableEntry)的指针,然后就可以通过指针来调用类的成员结构,从而实现代码重用,并且也让代码的可读性得到了提高。
例如,原先的操作也可以通过uint32 address = (PageTableEntry*)ptr->address()实现,而这种实现不但可以实现address()的重用,还一下就能够看出语句的目的是获得页表项中存储的地址。
而static PageTableEntry* from(uint32 addr);这样的函数其实就是为了我们能够更方便也更美观地进行指针的类型转换:PageTableEntry::from(ptr)肯定要比(PageTableEntry*)ptr看起来更合理,并且在某些特定的情形下,这样的转换函数内还可以添加额外的判断,让类型的转换更加安全。
PageTableEntry类的全部定义如下:
1 | class PageTableEntry { |
其中函数的实现如下:
1 | PageTableEntry* PageTableEntry::from(uint32 addr) { |
而对于页表而言,它的实现就更加简单了,由于它在 的页大小下本质就是一个长度位1024的数组,所以其成员变量就是一个长度为1024的数组变量:
1 | class PageTable { |
而由于页表本身不需要实现太多的功能,在目前实验中只需要对页表进行初始化以及取出页表中的第idx个页表项,所以其成员函数也十分简单:
1 | public: |
除此之外,由于页表可能是一级页表也可能是二级页表,对于一级页表而言,一般一级页表都是直接拿到地址,所以需要添加一个由32位地址转换为页表对象指针的静态成员函数;而二级页表都是要从一级页表中获得了页表项,解析出地址,然后再转换为二级页表对象的指针,稍微有点麻烦,所以不妨添加一个由PageTableEntry类的对象直接转换为页表对象指针的静态成员函数。
1 | public: |
完整的PageTable类定义如下:
1 | class PageTable { |
其中的成员函数实现如下:
1 | PageTable* PageTable::from(const PageTableEntry& entry) { |
勇者奖章
恭喜你,读完了所有日志中最长最复杂的一篇,后面的实验之路将会因这一章的努力而愈发平坦。
